


IV. Principe général▲
Qu'est-ce que finalement une "donnée" ? Une donnée est un ensemble de propriétés, proposant des fonctions (membres) pour les consulter, les positionner ou les manipuler en interne. Comme un livre qui possède un titre, un éditeur, un auteur etc. Chaque propriété peut soit caractériser la donnée (le titre du livre), soit référencer une autre donnée (l'auteur du livre) via un ou plusieurs identifiants.
IV-A. Les propriétés▲
Intéressons nous au plus bas niveau, la propriété. Comme tout bon développeur orienté objet, nous commençons par lui définir ses responsabilités :
- Encapsuler un type de valeur et lui donner accès
- Notifier tout changement
- Se charger/s'obtenir par chaîne de caractère
- Se charger/d'obtenir en binaire
Les propriétés pourront alors encapsuler un entier, un booléen, un string mais aussi peut-être des valeurs métiers ? Nous n'allons pas créer une propriété par type encapsulé, mais créer un modèle de propriété donc le paramètre Template sera la type de la valeur. Par la suite, nous aurons à les manipuler de manière générique, à les stocker ensemble, qu'elles soient propriétés de int, float ou bool ce qui nous amène à user du Type Erasure.
Voyons un début de code de la classe de base.
/*!
* \brief Classe de base des propriétés.
*/
class IProperty
{
public:
/*!
* \brief Constructeur.
*/
IProperty();
/*!
* \brief Obtient cette propriété sous forme de chaîne de caractères.
*
* \return Cette propriété sous forme de chaîne de caractères.
*/
virtual std::string ToString() const = 0;
/*!
* \brief Charge cette propriété à partir de sa représentation en chaîne de caractères.
*
* \param [in] rstrValue La représentation en chaîne à charger.
*/
virtual void FromString(const std::string& rstrValue) = 0;
/*!
* \brief Charge la propriété à partir d'une donnée binaire.
*
* \param pVoid Un pointeur vers la donnée binaire.
*/
virtual void FromVoid(void* pVoid) = 0;
protected:
static CStringExtractor s_oExtractor; /*!< L'extracteur de chaîne des propriétés. */Pour gérer le système d'écoute d'une propriété, nous utilisons le pattern Observer.
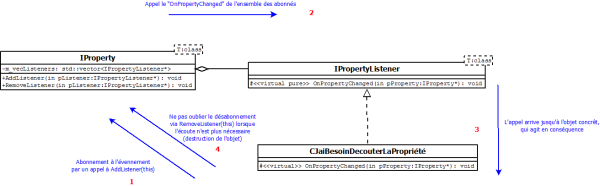
Définissons alors l'interface d'écoute des propriétés
class IProperty;
/*!
* \brief Interface d'écoute d'une propriété.
*/
class IPropertyListener
{
friend class IProperty;
protected:
/*!
* \brief Destructeur.
*/
virtual ~IPropertyListener();
/*!
* \brief Callback exécuté lorsqu'une propriété a changé de valeur.
*
* \param [in] poProperty La propriété.
*/
virtual void OnPropertyChanged(IProperty* poProperty) = 0;
};Ainsi que le branchement/débranchement et le stockage de ces écouteurs au sein de la propriété.
class IProperty
{
public:
/*!
* \brief Ajoute un écouteur à cette propriété.
*
* \param [in] poListener L'écouteur.
*/
void AddListener(IPropertyListener* poListener);
/*!
* \brief Retire un écouteur.
*
* \param [in] poListener L'écouteur à retirer.
*/
void RemoveListener(IPropertyListener* poListener);
protected:
/*!
* \brief Notifie les écouteurs que cette propriété a changé.
*/
void NotifyValueChanged();
private:
typedef std::map<IPropertyListener*, bool> TMapPropertyListener; /*!< Type du container des écouteurs de propriétés. */
TMapPropertyListener m_mapPropertyListeners; /*!< La liste des écouteurs. */
};L'ajout/retrait d'écouteur s'implémente ainsi :
void IProperty::AddListener(IPropertyListener* poListener)
{
if(m_mapPropertyListeners.find(poListener) == m_mapPropertyListeners.end())
m_mapPropertyListeners.insert(std::make_pair<IPropertyListener*, bool>(poListener, false));
}
void IProperty::RemoveListener(IPropertyListener* poListener)
{
if(m_mapPropertyListeners.empty())
return;
TMapPropertyListener::iterator it = m_mapPropertyListeners.find(poListener);
if(it == m_mapPropertyListeners.end())
return;
m_mapPropertyListeners.erase(it);
}Et la notification comme cela :
void IProperty::NotifyValueChanged()
{
TMapPropertyListener::iterator it = m_mapPropertyListeners.begin();
TMapPropertyListener::iterator nextIt;
while(it != m_mapPropertyListeners.end())
{
nextIt = ++it; --it;
if(it->first && !IsLocked(it->first))
it->first->OnPropertyChanged(this);
it = nextIt;
}
}NotifyValueChanged est protégée car ce sera à la responsabilité des propriétés concrètes d'indiquer lorsque leur valeur a été modifiée.
Rajoutons maintenant quelques méthodes de manipulation.
/*!
* \brief Positionne la valeur de cette propriété par une propriété abstraite.
* Si les propriétés sont de même types, la valeur sera recopiée, sinon la valeur sera convertie en chaîne puis réimportée.
*
* \param rProperty La propriété dont la valeur est à affecter à celle-ci.
*/
virtual void Set(const IProperty& rProperty) = 0;
/*!
* \brief Indique si cette propriété représente une valeur numérique.
*
* \return true si sa valeur est numérique, sinon false.
*/
virtual bool IsNum() const = 0;
/*!
* \brief Compare cette propriété avec une autre, abstraite.
* Si les deux propriétés sont de même type, elles seront comparées entre elles, sinon via leurs équivalences alphanumériques.
*
* \param rProperty La propriété avec laquelle comparer celle-ci.
* \return Une valeur positive si cette propriété est plus grande, négative si plus petite, 0 en cas d'égalité.
*/
virtual int Compare(const IProperty& rProperty) const = 0;Désormais, nous pouvons généraliser cette classe afin de créer de nouvelles propriété. Commençons avec cette classe modèle qui va pouvoir être utilisé pour tous les types primitifs.
/*!
* \brief Représente une propriété typée.
*
* \tparam T Le type de donnée encapsulée par cette propriété.
*/
template<class T>
class CProperty : public IProperty
{
public:
typedef T value_type; /*!< Type de la valeur encapsulé, soit T */
/*!
* \brief Constructeur.
*
* \param [in] rtValue La valeur initiale.
*/
CProperty(T& rtValue = T());
/*!
* \brief Obtient cette propriété sous forme de chaîne de caractères.
*
* \return Cette propriété sous forme de chaîne de caractères.
*/
inline virtual std::string ToString() const;
/*!
* \brief Charge cette propriété à partir de sa représentation en chaîne de caractères.
*
* \param [in] rstrValue La représentation en chaîne à charger.
*/
inline virtual void FromString(const std::string& rstrValue);
/*!
* \brief Charge cette propriété à partir de sa représentation binaire.
*
* \param [in] pVoid La représentation binaire à charger.
*/
inline virtual void FromVoid(void* pVoid);
/*!
* \brief Définit la valeur de cette propriété.
*
* \param [in] rtValue La valeur.
*/
inline void SetValue(T& rtValue);
/*!
* \brief Obtient la valeur de cette propriété.
*
* \return La valeur.
*/
inline T& GetValue() const;
/*!
* \brief Positionne la valeur de cette propriété par une propriété abstraite.
* Si les propriétés sont de même types, la valeur sera recopiée, sinon la valeur sera convertie en chaîne puis réimportée.
*
* \param rProperty La propriété dont la valeur est à affecter à celle-ci.
*/
virtual void Set(const IProperty& rProperty);
/*!
* \brief Indique si cette propriété représente une valeur numérique.
*
* \return true si sa valeur est numérique, sinon false.
*/
virtual bool IsNum() const;
/*!
* \brief Compare cette propriété avec une autre, abstraite.
* Si les deux propriétés sont de même type, elles seront comparées entre elles, sinon via leurs équivalences alphanumériques.
*
* \param rProperty La propriété avec laquelle comparer celle-ci.
* \return Une valeur positive si cette propriété est plus grande, négative si plus petite, 0 en cas d'égalité.
*/
virtual int Compare(const IProperty& rProperty) const;
private:
T m_tValue; /*!< La valeur de cette propriété. */
};Concernant le chargement via le binaire, la plupart des types n'auront qu'à recopier la mémoire à partir de "pVoid", et ce jusque pVoid + taille du type. Mais concernant le type "std::string", ce pVoid sera un "char*". Utilisons alors la technique des Pour résoudre ce problème, voyons les classes politiques pour définir une règle "générale" pour tous les types, ainsi qu'une spécialisation pour "std::string".
template<class T>
struct SPropertyHelper
{
static T FromVoid(void* pVoid)
{
T tValue;
memcpy(&tValue, pVoid, sizeof(T));
return tValue;
}
};
template<>
struct SPropertyHelper<std::string>
{
static std::string FromVoid(void* pVoid)
{
return (char*)pVoid;
}
};Nous simplifiant l'implémentation de FromVoid à :
template<class T>
inline void CProperty<T>::FromVoid(void* pVoid)
{
SetValue(SPropertyHelper<T>::FromVoid(pVoid));
}Utilisons la même technique pour la méthode IsNum :
/*!
* \brief Structure indiquant si un type est numérique.
*
* \tparam T Le type.
*/
template <class T>
struct SIsInteger
{
/*!
* \brief Enumération ayant pour seul valeur la réponse à "est-ce que T est numérique".
*/
enum
{
value = false /*!< true si T est numérique, sinon false. */
};
};
/*!
* \brief Spécialisation pour les entiers signés.
*/
template<>
struct SIsInteger<int>
{
enum { value = true };
};
/*!
* \brief Spécialisation pour les entiers non signés.
*/
template<>
struct SIsInteger<unsigned int>
{
enum { value = true };
};
/*!
* \brief Spécialisation pour les entiers "court" signés.
*/
template<>
struct SIsInteger<short>
{
enum { value = true };
};
/*!
* \brief Spécialisation pour les entiers "court" non signés.
*/
template<>
struct SIsInteger<unsigned short>
{
enum { value = true };
};
/*!
* \brief Spécialisation pour les entiers "long".
*/
template<>
struct SIsInteger<long>
{
enum { value = true };
};
/*!
* \brief Spécialisation pour les entiers "long" non signés.
*/
template<>
struct SIsInteger<unsigned long>
{
enum { value = true };
};
/*!
* \brief Structure indiquant si un type est numérique flottant.
*
* \tparam T Le type.
*/
template <class T>
struct SIsFloat
{
/*!
* \brief Enumération ayant pour seul valeur la réponse à "est-ce que T est numérique flottant".
*/
enum
{
value = false /*!< true si T est numérique flottant, sinon false. */
};
};
/*!
* \brief Spécialisation pour les flottant.
*/
template<>
struct SIsFloat<float>
{
enum { value = true };
};
/*!
* \brief Spécialisation pour les flottant à double précision.
*/
template<>
struct SIsFloat<double>
{
enum { value = true };
};Produisant cet implémentation :
template<class T>
bool CProperty<T>::IsNum() const
{
return SIsInteger<T>::value || SIsFloat<T>::value;
}Pour les comparaisons ainsi que les positionnements via des IProperty, nous utilisons les RTTI pour savoir si la propriété est du même type auquel cas on passera par un downcast, sinon via les chaînes de caractères :
template<class T>
void CProperty<T>::Set(const IProperty& rProperty)
{
if(typeid(*this) == typeid(rProperty))
SetValue((static_cast<const CProperty<T>&>(rProperty)).GetValue());
else
FromString(rProperty.ToString());
}
template<class T>
int CProperty<T>::Compare(const IProperty& rProperty) const
{
if(typeid(*this) == typeid(rProperty))
return STypeComparator<T>::Compare(GetValue(), (static_cast<const CProperty<T>&>(rProperty)).GetValue());
else
return ToString().compare(rProperty.ToString());
}Ce qui nous permettra de comparer des int avec des short ou autre :
CProperty<int> prop1(4);
CProperty<long> prop2(4);
CProperty<std::string> prop3("4");
if(prop1.Compare(prop2)) { ... }
if(prop1.Compare(prop3)) { ... }
Il reste un petit point qui dérange, ce sont ces "const T&".
En effet, lors de l'appel d'une fonction, les paramètres sont copiés. Lorsque nous passons par valeur, toute la valeur de l'objet est recopiée, c'est donc pour ça qu'il est plus judicieux de passer par pointeur ou référence (constant(e) si l'objet pointé ne doit pas être modifié).
Dans la plupart des cas, le gain en performance est réel. En revanche, cela peut être moins performant, si nous passons une référence ou un pointeur d'un type dont la taille est inférieure à celle d'un pointeur/référence, soit 8 octets.
Dans le cas d'un entier ou d'un booléen qui ne nécessiterait que respectivement 4 et 1 octets, nous y perdons.
Plus de détails dans ce cours sont disponibles.
Alors comment savoir s'il faut passer par valeur ou par référence ? Et ce, tout est restant générique ? C'est là qu'intervient une petite astuce détaillée dans l'article de Alp, moyennant quelques lignes de méta programmation.
Analysons ce code :
template<bool B> std::string VraiOuFaux() { return "vrai"; };VraiOuFaux est une méta fonction (une fonction prenant un paramètre Template). A ce stade, que B prenne la valeur "true" ou "faux", la même fonction sera appelé et renverra... "vrai". Pour gérer le cas "faux", spécialisons la fonction.
template<> std::string VraiOuFaux<false>() { return "faux"; };Désormais avec une valeur "true", l'appel ira dans la fonction générique, en revanche avec le paramètre "false", le compilateur trouvera une spécialisation qui sera privilégiée.
assert(VraiOuFaux<true>() == "vrai");
assert(VraiOuFaux<false>() == "faux")Regroupons maintenant ces deux méta-fonctions dans une structure composée d'une seconde structure qui va accueillir un booléen. Le paramètre booléen indique s'il faut sélectionner par valeur ou par référence.
template <typename T>
struct SParamHelper
{
template <typename U, bool ByRef> // Par défaut, nous passons par référence
struct SPrivateParamHelper
{
typedef const U& value_type;
};
template <typename U>
struct SPrivateParamHelper<U, false> // Mais si le flag est à "faux", nous passons par valeur.
{
typedef U value_type;
};
};Maintenant, nous pouvons appeler SParamHelp avec le type concerné, il reste à utiliser l'une ou l'autre spécialisation en jouant sur le booléen. Quand le type dépasse 8 octets, nous passons par référence, sinon par valeur.
typedef typename SPrivateParamHelper<T, (sizeof(T) > 8)>::value_type param_type;Voici le rendu :
/*!
* \brief Représente une propriété typée.
*
* \tparam T Le type de donnée encapsulée par cette propriété.
*/
template<class T>
class CProperty : public IProperty
{
public:
typedef T value_type; /*!< Type de la valeur encapsulé, soit T */
typedef typename SParamHelper<T>::param_type param_type; /*!< Type des paramètres à travailler (par valeur ou référence). */
/*!
* \brief Constructeur.
*
* \param [in] tValue La valeur initiale.
*/
CProperty(param_type tValue = T());
/*!
* \brief Obtient cette propriété sous forme de chaîne de caractères.
*
* \return Cette propriété sous forme de chaîne de caractères.
*/
inline virtual std::string ToString() const;
/*!
* \brief Charge cette propriété à partir de sa représentation en chaîne de caractères.
*
* \param [in] rstrValue La représentation en chaîne à charger.
*/
inline virtual void FromString(const std::string& rstrValue);
/*!
* \brief Charge cette propriété à partir de sa représentation binaire.
*
* \param [in] pVoid La représentation binaire à charger.
*/
inline virtual void FromVoid(void* pVoid);
/*!
* \brief Définit la valeur de cette propriété.
*
* \param [in] tValue La valeur.
*/
inline void SetValue(param_type tValue);
/*!
* \brief Obtient la valeur de cette propriété.
*
* \return La valeur.
*/
inline param_type GetValue() const;
/*!
* \brief Positionne la valeur de cette propriété par une propriété abstraite.
* Si les propriétés sont de même types, la valeur sera recopiée, sinon la valeur sera convertie en chaîne puis réimportée.
*
* \param rProperty La propriété dont la valeur est à affecter à celle-ci.
*/
virtual void Set(const IProperty& rProperty);
/*!
* \brief Indique si cette propriété représente une valeur numérique.
*
* \return true si sa valeur est numérique, sinon false.
*/
virtual bool IsNum() const;
/*!
* \brief Compare cette propriété avec une autre, abstraite.
* Si les deux propriétés sont de même type, elles seront comparées entre elles, sinon via leurs équivalences alphanumériques.
*
* \param rProperty La propriété avec laquelle comparer celle-ci.
* \return Une valeur positive si cette propriété est plus grande, négative si plus petite, 0 en cas d'égalité.
*/
virtual int Compare(const IProperty& rProperty) const;
private:
T m_tValue; /*!< La valeur de cette propriété. */
};Rajoutons des opérateurs de comparaison et d'égalité pour pouvoir comparer par exemple des CProperty<long> avec des long etc.
/*!
* \brief Représente une propriété typée.
*
* \tparam T Le type de donnée encapsulée par cette propriété.
*/
template<class T>
class CProperty : public IProperty
{
public:
/*!
* \brief Opérateur d'égalité avec une valeur de même type que celle encapsulée.
*
* \param [in] rtValue la valeur avec laquelle comparer celle-ci.
* \return true si les deux valeurs sont égales, sinon false.
*/
bool operator ==(param_type rtValue) const;
/*!
* \brief Opérateur d'égalité.
*
* \param [in] rProperty la propriété avec laquelle comparer celle-ci.
* \return true si les deux propriétés sont égales, sinon false.
*/
bool operator ==(const CProperty<T>& rProperty) const;
/*!
* \fn bool operator !=(const CProperty<T>& roProperty) const
* \brief Opérateur d'inégalité.
*
* \param [in] rProperty la propriété avec laquelle comparer celle-ci.
* \return true si les deux propriétés sont différentes, sinon false.
*/
bool operator !=(const CProperty<T>& rProperty) const;
/*!
* \brief Opérateur d'affectation =
*
* \return Cette propriété après avoir affecté la nouvelle valeur.
*/
param_type operator =(param_type rtValue);
/*!
* \brief Opérateur d'addition +
*
* \param rtValue La valeur à ajouter
* \return La résultante de l'addition.
*/
CProperty<T> operator+(param_type rtValue);
/*!
* \brief Opérateur de soustraction -
*
* \param rtValue La valeur à soustraire.
* \return La résultante de la soustraction.
*/
CProperty<T> operator-(param_type rtValue);
/*!
* \brief Opérateur d'affectation =
*
* \return Cette propriété après avoir affecté la nouvelle valeur.
*/
const CProperty<T>& operator =(const CProperty<T>& rtValue);
};Puis des raccourcits pour qu'à l'utilisation, le code soit plus propre.
typedef CProperty<int> TInt32Property; /*!< Type de propriété d'entier signé. */
typedef CProperty<unsigned int> TUInt32Property; /*!< Type de propriété d'entier non signé. */
typedef CProperty<_int64> TInt64Property; /*!< Type de propriété d'entier long signé. */
typedef CProperty<unsigned _int64> TUInt64Property; /*!< Type de propriété d'entier long non signé. */
typedef CProperty<bool> TBoolProperty; /*!< Type de propriété de booléen. */
typedef CProperty<float> TFloatProperty; /*!< Type de propriété de flottant signé. */
typedef CProperty<double> TDoubleProperty; /*!< Type de propriété de flottant à double précision. */
typedef CProperty<char> TCharProperty; /*!< Type de propriété de caractère signé. */
typedef CProperty<unsigned char> TUCharProperty; /*!< Type de propriété de caractère non signé. */
typedef CProperty<short> TShortProperty; /*!< Type de propriété d'entier court signé. */
typedef CProperty<unsigned short> TUShortProperty; /*!< Type de propriété d'entier court non signé. */
typedef CProperty<std::string> TStringProperty; /*!< Type de propriété de chaîne de caractère. */Jusqu'ici, nous n'avons rien fait concernant la gestion des données, juste préparé les utilitaires dont nous auront besoin. Par conséquent, ces classes ci dessus sont intégrées dans notre bibliothèque d'utilitaires, kinUtils.
IV-B. Les données▲
C'est à partir de là que ça commence à se corser un peu, nous entrons dans la seconde bibliothèque, kinGesDatas.
Une donnée a donc des propriétés :
class CBook
{
public:
// accesseurs
// fonctions métier
private:
TUInt64Property m_ulIdent;
TStringProperty m_strLogin;
TStringProperty m_strPass;
TUShortProperty m_usAge;
};
Ces propriétés, il va falloir les remplir avec les informations contenues dans une source de données, sous forme de chaîne de caractères ou binaire.
Pour relier la source aux propriétés, nous avons besoin d'un mappage entre des champs en base, de fichiers plats, des balises XML etc. Il va donc falloir les nommer ces propriétés puis y accéder par leur nom. Les données seront typées, mais ces fonctions devront être accessibles à un niveau plus abstrait. Réutilisons le Type Erasure et créons alors une classe de base des données.
class IData
{
public:
virtual IProperty* GetProperty(const std::string& rstrPropertyName) = 0;
};
Depuis cette interface, hériteront les classes métiers (CBook, CAuthor, CCar, CUser etc.). Dans notre bibliothèque, elle se gèreront toutes de la même manière mais à ce stade, nous ne savons pas encore ce qu'elles représentent étant donnée qu'elles appartiennent à la bibliothèque métier, de plus haut niveau.
En fait, comme nous ne connaîssons pas les types exactes des données, nous allons gérer des données de "nous ne savons pas quoi".
Construisons maintenant une classe concrète, de données de "nous ne savons pas quoi", appelée ici "T" :
template<class T>
class CData : public IData
{
public:
virtual IProperty* GetProperty(const std::string& rstrPropertyName);
protected:
CData();
};
Le constructeur est protégé car les données ne pourront être créées que par des accréditeurs, en l'occurrence ici, les chargeurs de données. En effet, les données seront représentatives des informations contenues dans les sources. Si nous laissons la possibilité d'en créer autrement que via les sources, la cohérence de notre système n'est plus assurée.
La donnée métier pourra donc hérite donc de cette classe comme ceci :
class CBook : public CData<CBook>
{
public:
// accesseurs
// fonctions métier
private:
TUInt64Property m_ulIdent;
TStringProperty m_strTitle;
TStringProperty m_strDescription;
TUInt32Property m_uiYear;
TUInt64Property m_ulIdentAuthor;
};Nous devons désormais "nommer" ces données pour relier un type tel que CBook à une chaîne telle que "CBOOK" qui sera référencé dans des fichiers text/xml à l'extérieur. Maintenant c'est de l'acquis, pour lier une classe à "quelque chose", dans notre cas un code, nous utilisons les classes politiques.
/*!
* \brief structure indiquant un code identifiant d'un type.
*
* \tparam Le type de donnée.
*/
template<class T>
struct SDataTrait
{
static const char* CODE; /*!< Le code de la donnée T */
};Le nommage se fait alors ainsi :
const char* datas::SDataTrait<CBook>::CODE = "BOOK";
Un truc supplémentaire à penser mais bon... en cas d'oubli, comme nous n'avons pas implémenter de cas standard, le compilateur sera préventif.
Les propriétés doivent également être nommées pour être référencée elles aussi dans des fichiers de configuration. Pour se faire, basons nous sur un dictionnaire prenant le nom en clé et la propriété en valeur.
template<class T>
class CData : public IData
{
public:
virtual IProperty* GetProperty(const std::string& rstrPropertyName);
protected:
std::map<std::string, IProperty&> m_mapProperties;
};
template<class T> IProperty* CData<T>::GetProperty(const std::string& rstrPropertyName)
{
return &(m_mapProperties[rstrPropertyName]);
}
CBook::CBook()
{
m_mapProperties["ID"] = m_ulIdent;
m_mapProperties["TITLE"] = m_strTitle;
m_mapProperties["DESCRIPTION"] = m_strDescription;
m_mapProperties["YEAR"] = m_uiYear;
m_mapProperties["ID_AUTHOR"] = m_ulIdentAuthor;
}
En fait nous avons tout faux, je l'ai fait avant de m'apercevoir...
En effet, en procédant ainsi, nous sommes partis pour dupliquer la table des propriétés dans chaque objet à gérer. Faisons un petit calcul. Admettons nous avons 3000 livres à gérer. Les noms prennent en tout 40 octets, et la référence 8 de plus ce qui ramène
l'utilisation mémoire à 3000 * (40 + 8) = 144ko, sans parler de la gestion interne des dictionnaires de la STL. C'est pas grand chose, mais nous nous apprêtons à faire quelque chose d'assez robuste pour gérer des centaines de milliers de données, et à ce niveau, les pertes s'évaluent en dizaines de méga octets.
Alors comment faire ? Représentons nous graphiquement par un tableau ce que nous avons fait :
| ID | TITLE | DESCRIPTION | YEAR | ID_AUTHOR |
| 1 | 99 francs | Octave est un publicitaire blasé par le monde du maketing qui... | 2000 | 25 |
| ID | TITLE | DESCRIPTION | YEAR | ID_AUTHOR |
| 2 | C++ pour les Nuls | Apprenez efficacement les rouages de C++ dans un... | 2006 | 37 |
| ID | TITLE | DESCRIPTION | YEAR | ID_AUTHOR |
| 3 | Candide | Candide, un jeune homme à la vie heureuse, se voit basculé dans... | 1759 | 14 |
En faite ce qu'il nous faut, c'est une entête (les noms de propriétés) puis une ligne par donnée. Le titre du livre 2 est donc placé aux coordonnées (2, "TITLE").
Dans un tableau "normal", pour obtenir une valeur, nous cherchons la colonne correspondante, puis la ligne de la donnée. En C++, cette entête pourra être un dictionnaire entre un nom, et un pointeur de membre. Ainsi, avec le nom, nous récupérons le pointeur de membre et appliqué à la donnée, la valeur sous forme de propriété.
Pour schématiser ce qu'est un pointeur de membre, voici un dessin.

Et un bout de code pour mieux se représenter
class CTestMemPtr
{
public:
CTestMemPtr(int i, float f, const std::string& rstr)
: m_i(i), m_f(f), m_str(rstr) { }
int m_i;
float m_f;
std::string m_str;
};
void Test()
{
// Pointeurs sur les membres de la classe CTestMemPtr
int CTestMemPtr::*MemPtr1 = &CTestMemPtr::m_i;
float CTestMemPtr::*MemPtr2 = &CTestMemPtr::m_f;
std::string CTestMemPtr::*MemPtr3 = &CTestMemPtr::m_str;
// Création des objets
CTestMemPtr oTest1(1, 2.2f, "3");
CTestMemPtr oTest2(4, 5.5f, "6");
CTestMemPtr oTest3(7, 8.8f, "9");
// Récupération des valeurs
int iEntierDeTest2 = oTest2.*MemPtr1; // Renvoi bien 4
float fFlottantDeTest3 = oTest3.*MemPtr2; // Renvoi bien 8.8f
std::string strChaineDeTest1 = oTest1.*MemPtr3; // Renvoi bien "3"
}
Voilà pour le principe. Dans cette exemple, nous voyons qu'il faut un type de pointeur de membre par type de membre. Or, pour nous, les membres dont nous nous intéresseront seront des propriétés, toutes issues d'une même interface, IProperty.
Aussi, dans l'exemple j'ai mis les membres en accès public ce qui ne serait pas correct pour les classes métier de notre utilisateur. Alors, il va falloir que la donnée CData<T> soit amie avec les classes qui auront besoin d'accéder à ses membres, soit les classes de chargement et de gestion.
Notre classe de donnée évolue alors comme ceci :
template<class T>
class CData : public IData
{
friend class CClasseIO; // Nous verrons plus tard le côté IO
public:
typedef typename IProperty CData<T>::*TPropertyMemPtr; /*!< Type d'un pointeur sur une propriété membre de ce type de donnée. */
};
template<class T> IProperty& CData<T>::GetProperty(const std::string& rstrPropertyName)
{
return this->*(LesNomsDeProprietesDeTQuelquepartQueNousVerronsApres[rstrPropertyName]);
}Pour conclure ce point, la table de correspondance entre notre entête (les noms de propriété) et les données (via des pointeurs de membre), bref, la colonne de notre tableau fictif, ne sera pas stockée à l'échelle de la donnée (de la ligne). Nous verrons ça une fois la notion de gestionnaires introduite.
IV-C. Le gestionnaire▲
IV-C-1. Introduction▲
Maintenant que nous avons des données, il va falloir les gérer, c'est à dire les charger, sauvegarder, supprimer dans la source de données mais aussi les stocker, effectuer des recherches etc.
Précédemment, nous avons vu que nous gérons en fait des données de "nous ne savons pas trop quoi". Nous allons donc faire des gestionnaires de données de "nous ne savons pas trop quoi", symbolisées par "T".
Comme un gestionnaire est encore une fois une classe Template, le compilateur va générer autant de gestionnaire qu'il y a de type de donnée à gérer.
Mais nous aurons besoin de ne pas en faire de distinction à l'utilisation, nous allons donc les réunir sous une interface que nous alimenterons au fur et à mesure que nous en aurons besoin. Au début, nous la laissons vide.
/*!
* \brief Interface des gestionnaires de données.
*/
class IGesData
{
protected:
/*!
* \brief Constructeur.
*/
IGesData();
/*!
* \brief Destructeur.
*/
virtual ~IGesData();
};
/*!
* \brief Gestionnaire d'entités de type T.
*
* \tparam T Le type de donnée à gérer.
*/
template<class T>
class CGesData : public IGesData // Un gestionnaire de T, dont T sera un livre, un auteur etc...
{
public:
// Les méthodes de manipulation des T
};IV-C-2. Vue d'ensemble▲
Arrêtons nous là deux minutes, le temps de voir où nous en sommes en de récapituler notre architecture jusqu'ici.
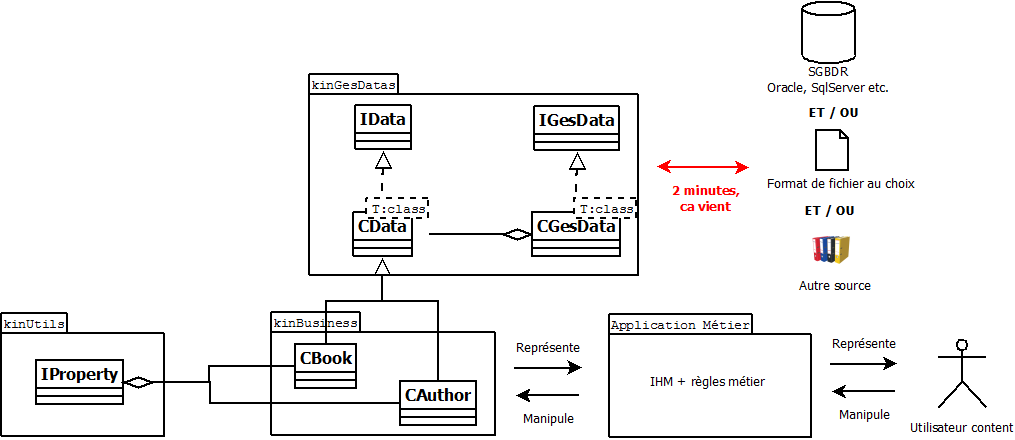
Avant d'entrer dans la notion de connecteurs, qui rapatrierons les données, préparons leur accueil au sein de notre bibliothèque.
IV-C-3. Stockage des données en mémoire▲
Avant d'offrir la manipulation des données, il faut d'abord pouvoir les stocker. Pour se faire, un std::vector est largement suffisant.
template<class T>
class CGesData : public IGesData
{
public:
/*!
* \brief Obtient le nombre de données.
*
* \return le nombre de données.
*/
unsigned long GetCount() const;
/*!
* \brief Obtient une donnée par son index.
*
* \param ulIndex L'index.
* \return La donnée.
*/
T* GetAt(unsigned long ulIndex) const;
private:
/*!
* \brief Ajoute une série de données.
*
* \param poData Un pointeur vers le tableau des données à ajouter.
* \param ulCount Le nombre de données.
*/
void AddData(CData<T>** poData, unsigned long ulCount);
/*!
* \brief Retire une série de données.
*
* \param poData Un pointeur vers le tableau des données à retirer.
* \param ulCount Le nombre de données.
*/
void RemoveData(CData<T>** poData, unsigned long ulCount);
typedef std::vector<CData<T>*> TVecDatas; /*!< Type du stockage des données. */
TVecDatas m_vecData; /*!< Liste des données. */
};
template<class T>
unsigned long CGesData<T>::GetCount() const
{
return static_cast<unsigned long>(m_vecData.size());
}
template<class T>
T* CGesData<T>::GetAt(unsigned long ulIndex) const
{
return static_cast<T*>(m_vecData[ulIndex]);
}
template<class T>
void CGesData<T>::AddData(CData<T>** poData, unsigned long ulCount)
{
std::copy(poData, poData + ulCount, std::back_inserter(m_vecData));
}
template<class T>
void CGesData<T>::RemoveData(CData<T>** poData, unsigned long ulCount)
{
for(unsigned long ulDataIt = 0; ulDataIt < ulCount; ulDataIt)
m_vecData.erase(std::remove(m_vecData.begin(), m_vecData.end(), poData[ulDataIt]), m_vecData.end());
}
Les méthodes d'ajout et de suppression sont privées car personne n'a le droit d'ajouter ou supprimer une donnée mise à part les modules IO.
IV-C-4. Le gestionnaire des gestionnaires▲
Imaginons nous avons 4 types de données à gérer, nous auront 4 gestionnaire différents. Ces gestionnaires devront être disponible partout dans l'application étant donnée qu'ils fournissent la matière première de l'ensemble de l'application appelante.
Nous avons vu le singleton, qui permettait d'assurer une instance unique d'une classe, disponible sur demande, partout dans le programme utilisateur, donc ce Pattern semble répondre à notre problème.
template<class T>
class CGesData : public IGesData, public CSingleton<CGesData<T>>Ce qui après compilation nous amènerai à cette conception.
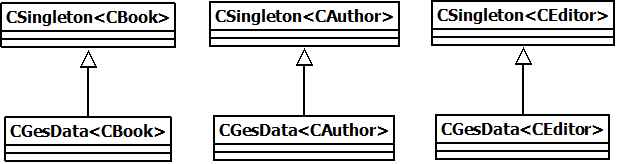
C'est plutôt moche n'est-ce pas ? En plus cela va contraindre à chaque fois à détruire chaque gestionnaire un par un. Trouvons autre chose.
Il nous faut un point d'entrée, donc une classe non templarisée, singleton.
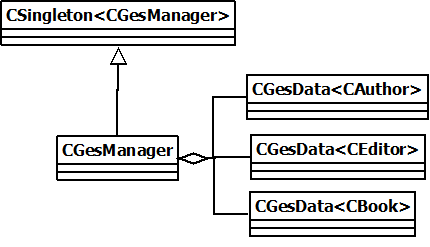
Nous nous rapprochons, mais en terme de code, cela donnerai ceci :
class CGesManager : public CSingleton<CGesManager>
{
public
template<class T> unsigned long GetCount()
{
if(stdcmp(CDataTrait<T>::CODE, "BOOK") == 0)
return m_gesBooks.GetCount();
else if(stdcmp(CDataTrait<T>::CODE, "AUTHOR") == 0)
return m_gesAuthors.GetCount();
else if(stdcmp(CDataTrait<T>::CODE, "EDITOR") == 0)
return m_gesEditors.GetCount();
else
throw ... ;
}
private:
CGesData<CBook> m_gesBooks;
CGesData<CAuthor> m_gesAuthors;
CGesData<CEditor> m_gesEditors;
};
Les gestionnaires vont posséder pas mal de méthodes, rien qu'à m'imaginer devoir faire cette cuisine pour chaque types, ça me donne des frissons, d'autant plus que nous sommes dans la bibliothèque de gestion, et non dans les données métiers, et si l'utilisateur a besoin de venir bidouiller ici pour intégrer ses données.... Trouvons autre chose.
Nous pourrions peut-être faire hériter notre point d'entrée de tous les gestionnaires, puis proposer des fonctions templarisées, de redirection vers le bon gestionnaire parent en utilisant le T. Voici ce que ça donnerai.
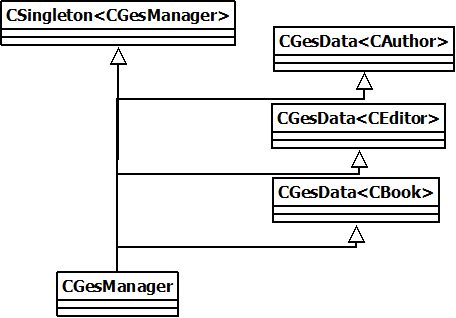
Voyons le code pour faire ça.
class CGesManager : public CSingleton<CGesManager>,
public CGesData<CBook>,
public CGesData<CAuthor>,
public CGesData<CEditor>
{
public
template<class T> unsigned long GetCount();
};
template<class T>
CGesManager::GetCount()
{
return CGesData<T>::GetCount();
}
Là c'est déjà bien mieux, mais ça impose à la bibliothèque des données métiers de venir dans la bibliothèque de gestion pour enregistrer ses types, ce qui n'est pas concevable.
Ce qui serait bien, ce serait de pouvoir lister les données à gérer, puis de "donner" cette liste à la bibliothèque qui va les gérer. Cela introduit les listes de types.
IV-C-4-1. Les listes de types▲
Retour à la méta programmation. Une liste possède un début, et une fin.
template<class T1, class T2>
struct STypeList
{
typedef T1 THead;
typedef T2 TTail;
};THead (la tête) et TTail (la queue) sont deux types. Pour en rajouter d'avantage, il faut que la queue soit une nouvelle liste. Pour terminer la liste, nous utiliseront un type NULL.
template<class T1, class T2>
struct STypeList
{
typedef T1 THead;
typedef T2 TTail;
};
struct SNullType{}
// Liste avec 1 éléments
typedef STypeList<CBook, SNullType> TOneElement;
// Liste avec 2 élements
typedef STypeList<CAuthor, TOneElement> TTwoElements;
// etc.
Ici, TTwoElements prend en tête CAuthor. Sa queue est une autre liste dont la tête est CBook. Enfin, la queue de la queue se termine par SNullType, mettant fin à la liste.
Nous pouvons en déduire une logique.
// 3 éléments
typedef STypeList<CBook, STypeList<CAuthor, STypeList<CEditor, SNullType>>> TThreeElements;
// En fait, pour n element nous aurons
typedef STypeList<n, STypeList<n-1>> TNElements;Pour agir sur ces types, il faut créer des structures qui utiliseront la récursivité, puis les spécialiser pour gérer la fin de la liste, soit le type SNullType. Voici quelques opérations :
// Ajout d'un type en fin de liste
template <class T, class TList> // T est le type à rajouter, TList est la liste à laquelle le rajouter.
struct SPushBack
{
// Nous définissons une liste commençant par le premier élément, puis nous récurçons pour construire la queue.
typedef STypeList<typename TList::THead, typename SPushBack<T, typename TList::TTail>::TResult> TResult;
};
template <class T>
struct SPushBack<T, SNullType>
{
// Arrivé au dernier élément de la liste, nous stoppons la récursion et l'élément devient une liste de 1 élément, celui à rajouter
typedef STypeList<T, SNullType> TResult;
};
// exemple :
typedef STypeList<CBook, SNullType> TOneElement;
typedef SPushBack<CAuthor, TOneElement> TTwoElements;
// Concaténation
template <class TList1, class TList2>
struct SConcat
{
// Même opération qu'au dessus, sauf que nous ajoutons les types 1 par 1 par la récursion.
typedef typename SConcat<typename SPushBack<typename TList2::THead, TList1>::TResult, typename TList2::TTail>::TResult TResult;
};
template <class TList1>
struct SConcat<TList1, SNullType>
{
// Puis nous nous arrêtons lorsque nous trouvons le type SNullType
typedef TList1 TResult;
};
// exemple :
typedef STypeList<CBook, STypeList<CAuthor, SNullType>> TTwoElements;
typedef STypeList<CEditor, STypeList<CCustomer, SNullType>> TTwoElementsAgain;
typedef SConcat<TTwoElements, TTwoElementsAgain>::TResult TFourElements;A cela, rajoutons quelques macro pour offrir un code plus facile à maîtriser :
#define TTYPELIST_1(t1) STypeList<t1, SNullType> /*!< Définit une liste d'un seul type. */
#define TTYPELIST_2(t1, t2) STypeList<t1, TTYPELIST_1(t2)> /*!< Définit une liste de deux types. */
#define TTYPELIST_3(t1, t2, t3) STypeList<t1, TTYPELIST_2(t2, t3)> /*!< Définit une liste de trois types. */
#define TTYPELIST_4(t1, t2, t3, t4) STypeList<t1, TTYPELIST_3(t2, t3, t4)> /*!< Définit une liste de quatre types. */
#define TTYPELIST_5(t1, t2, t3, t4, t5) STypeList<t1, TTYPELIST_4(t2, t3, t4, t5)> /*!< Définit une liste de cinq types. */
#define TTYPELIST_6(t1, t2, t3, t4, t5, t6) STypeList<t1, TTYPELIST_5(t2, t3, t4, t5, t6)> /*!< Définit une liste de six types. */
#define TTYPELIST_7(t1, t2, t3, t4, t5, t6, t7) STypeList<t1, TTYPELIST_6(t2, t3, t4, t5, t6, t7)> /*!< Définit une liste de sept types. */
#define TTYPELIST_8(t1, t2, t3, t4, t5, t6, t7, t8) STypeList<t1, TTYPELIST_7(t2, t3, t4, t5, t6, t7, t8)> /*!< Définit une liste de huit types. */
#define TTYPELIST_9(t1, t2, t3, t4, t5, t6, t7, t8, t9) STypeList<t1, TTYPELIST_8(t2, t3, t4, t5, t6, t7, t8, t9)> /*!< Définit une liste de neuf types. */
//exemple
TTYPELIST_3(CBook, CAuthor, CEditor) ListeDe3Elements.IV-C-4-2. Les hiérarchies▲
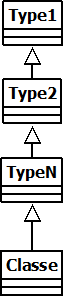
Grâce à ces listes de types, il est possible de construire toute une hiérarchie de classe. Il en existe deux types :
- Les hiérarchies linéaires - Fait hériter les types les uns après les autres.
- Les hiérarchies éparpillées - Fait hériter une classe de chaque types.
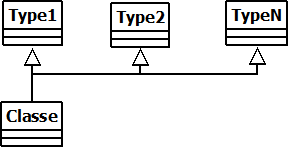
Analysons cette deuxième hiérarchie pour comprendre comment ça fonctionne.
Voici un peu de code.
// Définition d'une hiérarchie éparpillée
// TList est la liste des types, THandler est une classe template
template <class TList, template <class> class THandler> class CScatteredHierarchy;
// T1 et T2 sont deux types desquels hériter. Nous héritons donc de THandler<T1>, puis d'une sonconde hiérarchie qui héritera de THandler<T2>
// Comme c'est récursif, notre CScatteredHierarchie héritera à la fin de THandler<T1>, THandler<T2>, ..., THandler<Tn>
template <class T1, class T2, template <class> class THandler>
class CScatteredHierarchy<STypeList<T1, T2>, THandler> : public THandler<T1>, public CScatteredHierarchy<T2, THandler>
{
};
// Pour mettre fin à la récursion, nous spécialisons pour gérer la liste donc la queue est null (donc 1 élement)
template <class T, template <class> class THandler>
class CScatteredHierarchy<STypeList<T, SNullType>, THandler> : public THandler<T>
{
};
// Puis nous gèrons le cas pour une liste de 0 élément, le type SNullType
template <template <class> class THandler>
class CScatteredHierarchy<SNullType, THandler>
{
};Générons maintenant cette hiérarchie pour notre besoin.
/*!
* \brief Représente le gestionnaire des gestionnaires.
*/
class CGesManager : public CSingleton<CGesManager>, public CScatteredHierarchy<TGesList, CGesData>
{
public:
template<class T> unsigned long GetCount() const;
};
typedef GesMgr CGesManager::GetInstance()
template<class T> unsigned long CGesManager::GetCount() const
{
return CGesData<T>::GetCount(); // Appel une des classes mère. Le choix se fait selon T.
}TGesList ici sera la liste des types à gérer, fournit par la lib métier de cette manière.
#include "CBook.h"
#include "CAuthor.h"
#include "CEditor.h"
#include <kinUtils/Types/TypeList.h>
typedef TTYPELIST_3(CBook, CAuthor, CEditor) TGesList;
#include <kinGesDatas/CGesManager.h>
Un gestionnaire ne peut donc être construit que par le gestionnaire des gestionnaire, nous pouvons alors mettre son constructeur en protected afin de sécuriser un minimum et toujours être prévoyant au maximum.
Ainsi, pour gérer un nouveau type de donnée, l'utilisateur n'aura qu'à le rajouter dans la liste de SA bibliothèque. En plus d'être pratique à faire, ça sera pratique à utiliser, surtout lorsque le Template peut être déduit via les arguments, le code sera d'avantage homogène.
CBook book = [...];
CAuthor author = [...];
unsigned long ulBookCount = GesMgr.GetCount<CBook>(); // Ici nous n'avons pas le choix il faut spécifier explicitement le type
GesMgr.Update(book); // mais ici,
GesMgr.Update(author); // c'est royalLe seul inconvénient est qu'à chaque fois que nous ferons une méthode dans le gestionnaire, un faudra la reporter de la même manière dans notre classe point d'entrée, notre dieu de la gestion, le gestionnaire des gestionnaires. Par la suite, lorsque nous créerons une méthode dans CGesData<T>, nous supposerons l'ajout dans CGesManager.
Concernant la destruction, un appel à GesMgr.Destroy() détruira tous les gestionnaires de données, ces derniers étant ses parents.
IV-C-5. Mapping des propriétés▲
Nous cherchions tout à l'heure un endroit où définir notre "colonne" associant un nom de propriété et un pointeur de membre de la classe de donnée. Le gestionnaire est le meilleur endroit pour ça
template<class T>
class CGesData : public IGesData
{
public:
/*!
* \brief Enregistre une propriété.
*
* \param rstrPropertyName Le nom de la propriété.
* \param memPropertyPtr Le pointeur de membre de la propriété.
*/
void RegisterPropertyMemPtr(const std::string& rstrPropertyName, typename IProperty T::*memPropertyPtr);
/*!
* \brief Obtient la propriété d'une donnée, par son nom.
*
* \param poData La donnée.
* \param rstrPropertyName Le nom de la propriété.
* \return La propriété.
*/
IProperty* GetProperty(CData<T>* poData, const std::string& rstrPropertyName);
private:
typedef std::map<std::string, typename IProperty T::*> TMapPropertiesMemPtr; /*!< Type du mapping des propriétés et leur nom. */
TMapPropertiesMemPtr m_mapPropertiesMemPtr; /*!< Mapping des propriétés et de leur nom. */
};
template<class T> void CGesData<T>::RegisterPropertyMemPtr(const std::string& rstrPropertyName, typename IProperty T::*memPropertyPtr)
{
#ifdef _DEBUG
if(m_mapPropertiesMemPtr.find(rstrPropertyName) != m_mapPropertiesMemPtr.end())
Log << "La propriété " << rstrPropertyName << " de " << CDataTrait<T>::CODE << " est déjà enregistrée\r\n";
#endif
m_mapPropertiesMemPtr[rstrPropertyName] = memPropertyPtr;
}
template<class T> IProperty* CGesData<T>::GetProperty(CData<T>* poData, const std::string& rstrPropertyName)
{
if(m_mapPropertiesMemPtr.size() == 0)
throw CPropertiesNotRegistredException(CDataTrait<T>::CODE);
TMapPropertiesMemPtr::const_iterator it = m_mapPropertiesMemPtr.find(rstrPropertyName);
if(it == m_mapPropertiesMemPtr.end())
throw CPropertyNotFoundException(CDataTrait<T>::CODE, rstrPropertyName);
return &(((T*)poData)->*(it->second));
}
Nous allons maintenant jouer à nouveau avec les classes politiques pour enregistrer les propriétés.
/*!
* \brief Structure d'enregistrement des propriétés d'un type donnée.
*
* \tparam Le type de donnée.
*/
template<class T>
struct SPropertyRegistrer
{
/*!
* \brief Enregistre les propriétés du type T.
*/
static void RegisterProperties();
};Puis l'enregistrement à la responsabilité du métier :
template<> void SPropertyRegistrer<CBook>::RegisterProperties()
{
GesMgr.RegisterPropertyMemPtr<CBook>("ID", reinterpret_cast<IProperty CBook::*>(&CBook::m_ulIdent));
};Actuellement ça fonctionne, mais nous n'allons pas imposer ce genre de code exotique à l'utilisateur (il a autre chose à faire avec ses problématiques métier), nous allons faire des macros stylées MFC :
#define BEGIN_PROPERTY_MAP(Class) \
template<> void SPropertyRegistrer<Class>::RegisterProperties() {
#define REG_PROPERTY(Class, Key, Prop) GesMgr.RegisterPropertyMemPtr<Class>(Key, reinterpret_cast<IProperty Class::*>(&Class::Prop));
#define END_PROPERTY_MAP() }Rendant la déclaration de la table ainsi
BEGIN_PROPERTY_MAP(CBook)
REG_PROPERTY(CBook, "ID", m_ulIdent)
REG_PROPERTY(CBook, "TITLE", m_strTitle)
REG_PROPERTY(CBook, "DESCRIPTION", m_strDescription)
REG_PROPERTY(CBook, "YEAR", m_uiYear)
REG_PROPERTY(CBook, "ID_EDITOR", m_ulIdentEditor)
REG_PROPERTY(CBook, "ID_AUTHOR", m_ulIdentAuthor)
END_PROPERTY_MAP()Naturellement il faudra permettre l'accès aux membres privés de "Class", et plus généralement les données (puisque que d'autres aspects seront à mapper).
#define MAKE_DATA(Class) \
friend struct SPropertyRegistrer<Class>;Ainsi l'entête de la classe des livres deviendra ceci :
class CBook : public CData<CBook>
{
MAKE_DATA(CBook)
public:
unsigned _int64 GetIdent() const;
const std::string& GetTitle() const;
void SetTitle(const std::string& rstrTitle);
const std::string& GetDescription() const;
void SetDescription(const std::string& rstrDescription);
unsigned int GetYear() const;
void SetYear(unsigned int uiYear);
private:
TUInt64Property m_ulIdent;
TStringProperty m_strTitle;
TStringProperty m_strDescription;
TUInt32Property m_uiYear;
TUInt64Property m_ulIdentAuthor;
};Et son implémentation
BEGIN_PROPERTY_MAP(CBook)
REG_PROPERTY(CBook, "ID", m_ulIdent)
REG_PROPERTY(CBook, "TITLE", m_strTitle)
REG_PROPERTY(CBook, "DESCRIPTION", m_strDescription)
REG_PROPERTY(CBook, "YEAR", m_uiYear)
REG_PROPERTY(CBook, "ID_AUTHOR", m_ulIdentAuthor)
END_PROPERTY_MAP()
unsigned _int64 CBook::GetIdent() const
{
return m_ulIdent;
}
const std::string& CBook::GetTitle() const
{
return m_strTitle;
}
void CBook::SetTitle(const std::string& rstrTitle)
{
m_strTitle = rstrTitle;
}
const std::string& CBook::GetDescription() const
{
return m_strDescription;
}
void CBook::SetDescription(const std::string& rstrDescription)
{
m_strDescription = rstrDescription;
}
unsigned int CBook::GetYear() const
{
return m_uiYear;
}
void CBook::SetYear(unsigned int uiYear)
{
m_uiYear = uiYear;
}Maintenant nous pouvons ajouter un raccourcit au niveau de la donnée pour aller chercher les propriétés par leur nom et éviter sans cesse de taper directement dans le gestionnaire (le code en serait alourdit).
class IData
{
public:
/*!
* \brief Obtient une propriété de cette donnée, par son nom.
*
* \return La propriété.
*/
virtual IProperty* GetProperty(const std::string& rstrPropertyName) = 0;
};
template<class T>
class CData : public IData
{
public:
/*!
* \brief Obtient une propriété de cette donnée, par son nom.
*
* \return La propriété.
*/
virtual IProperty* GetProperty(const std::string& rstrPropertyName);
};
template <class T>
IProperty* CData<T>::GetProperty(const std::string& rstrPropertyName)
{
return CGesManager::GetInstance().GetProperty(this, rstrPropertyName);
}IV-C-6. L'identification des données▲
La plupart des données sont identifiables. Elles sont identifiable via une clé unique. Cette clé peut être composée d'une ou plusieurs propriétés. Pour les enregistrer, nous allons réutiliser la même technique que pour les propriétés, à savoir les lister dans le gestionnaire.
template<class T>
class CGesData : public IGesData
{
public:
/*!
* \brief Enregistre une propriété identifiante.
*
* \param rstrPropertyName Le nom de la propriété identifiante.
*/
void RegisterIdent(const std::string& rstrPropertyName);
private:
typedef std::vector<std::string> TVecIdents; /*!< Type de stockage des noms de propriétés identifiantes. */
TVecIdents m_vecIdents; /*!< Propriétés identifiantes. */
};
template<class T> void CGesData<T>::RegisterIdent(const std::string& rstrPropertyName)
{
#ifdef _DEBUG
if(m_mapPropertiesMemPtr.find(rstrPropertyName) == m_mapPropertiesMemPtr.end())
Log << "La propriété identifiante " << rstrPropertyName << " de " << CDataTrait<T>::CODE << " n'est pas une propriété\r\n";
#endif
m_vecIdents.push_back(rstrPropertyName);
}
template<class T>
struct SIdentRegistrer
{
static void RegisterIdents();
};Puis des macros pour apaiser le code utilisateur.
#define BEGIN_IDENT_LIST(Class) \
template<> void SIdentRegistrer<Class>::RegisterIdents() {
#define REG_IDENT(Class, Prop) CGesManager::GetInstance().RegisterIdent<Class>(Key);
#define END_IDENT_LIST() }Qu'il utilisera comme ceci
BEGIN_IDENT_LIST(CBook)
REG_IDENT(CBook, "ID")
END_IDENT_LIST()Puis nous autorisons l'accès à l'enregistrement des identifiants.
#define MAKE_DATA(Class) \
friend struct SPropertyRegistrer<Class>; \
friend struct SIdentRegistrer<Class>;Nous pouvons maintenant proposer la récupération d'une donnée par son ou ses identifiants.
template<class T>
class CGesData : public IGesData
{
public:
/*!
* \brief Obtient une donnée par son/ses identifiant(s).
*
* \param mapIdents Les couples identifiant/valeur.
* \return La donnée si elle a été trouvé sinon 0.
*/
T* GetFromIdentsStr(std::map<std::string, std::string>& mapIdents);
/*!
* \brief Obtient une donnée par son/ses identifiant(s).
*
* \param mapIdents Les couples identifiant/valeur.
* \return La donnée si elle a été trouvé sinon 0.
*/
T* GetFromIdents(std::map<std::string, IProperty&>& mapIdents);
};
template<class T> T* CGesData<T>::GetFromIdentsStr(std::map<std::string, std::string>& mapIdents)
{
TVecDatas::iterator it = m_vecData.begin();
while(it != m_vecData.end())
{
bool bFound = true;
TVecIdents::iterator itIdents = m_vecIdents.begin();
while(itIdents != m_vecIdents.end())
{
if((((T*)(*it))->*m_mapPropertiesMemPtr[*itIdents]).ToString() != mapIdents[*itIdents])
{
bFound = false;
break;
}
++itIdents;
}
if(bFound)
return static_cast<T*>(*it);
++it;
}
return 0;
}
template<class T> T* CGesData<T>::GetFromIdents(std::map<std::string, IProperty&>& mapIdents)
{
std::map<std::string, std::string> stringMap;
std::map<std::string, IProperty*>::iterator it = mapIdents.begin();
while(it != mapIdents.end())
{
stringMap[it->first] = it->second.ToString();
++it;
}
return *(GetFromIdents(stringMap));
}IV-C-7. Les itérateurs▲
Dans notre gestionnaires, nous avions donc, pour le moment :
- Une liste données
- Une liste de propriétés par type de donnée
- Une liste de propriétés identifiantes par type de donnée
Nous aurons besoin de parcourir régulièrement ces informations. Nous allons nous contenter des méthodes GetCount() et GetAt(index) mais, pour un parcours itératif, nous préfèrerons... bah un itérateur, qui permet d'obtenir un code plus agréable à lire, mais aussi plus performant.
template<class T>
class CDataIterator
{
public:
/*!
* \brief Constructeur.
*/
CDataIterator();
/*!
* \brief Obtient la donnée courante.
*
* \return La donnée courante.
*/
CData<T>* GetData() const;
/*!
* \brief Poursuite la lecture.
*/
void Next();
private:
typename CGesData<T>::TVecDatas& m_vecData; /*!< Les données surlesquelles itérer. */
typename CGesData<T>::TVecDatas::const_iterator m_iter; /*!< L'itérateur interne. */
};
template<class T>
CDataIterator<T>::CDataIterator()
: m_vecData(((CGesData<T>*)(&CGesManager::GetInstance()))->m_vecData)
{
m_iter = m_vecData.begin();
}
template<class T>
CData<T>* CDataIterator<T>::GetData() const
{
return m_iter == m_vecData.end() ? 0 : *m_iter;
}
template<class T>
void CDataIterator<T>::Next()
{
++m_iter;
}Ainsi pour parcourir les livres, nous ferons
CDataIterator<CBook> iter;
T* currentData = 0;
while((currentData = iter.GetData()) != 0)
{
std::cout << currentData->GetTitle();
iter.Next();
}
Pour faire un peut plus joli, nous pouvons implémenter, comme dans la STL, les opérateurs ++ et -- mais bon... rien ne vous en empêche, de mon côté je préfère rester dans le code "maison".
Nous ferons un itérateur pour parcourir les propriétés d'un type de données ainsi que ses propriétés identifiantes, les résultats d'une recherche etc.. Je ne détaillerai pas forcément le code de l'ensemble d'entre eux tant ils sont similaires.
IV-C-8. La recherche▲
La recherche de données est fortement appréciée. Dans une gestion bibliothécaire, nous pourrions avoir besoin de devoir récupérer l'ensemble des emprunts qui n'ont pas été rendu à temps, ou récupérer les clients les plus anciens pour leur faire bénéficier d'une offre promotionnelle, où bien ceux par tranche d'âge afin de leur envoyer de la pub sur certains livres etc., etc.
Nous avons donc un portefeuille de données, et il nous faut le filtrer afin de ne récupérer que les données qui nous intéresse, de manière ponctuel.
Un tel filtre ne s'appliquera que sur un seul type de donnée, et pourra avoir plusieurs formes ("égal à", "supérieur à", "inférieur à", "inégale à", ou perso métier ?).
La fonction de recherche s'appuiera sur le filtre, sans vraiment savoir ses caractéristiques, elle a juste besoin d'appeler leur méthode "IsOk()" pour savoir si ça passe ou pas.
Dernier point, un filtre peut être composé de plusieurs filtres (par exemple pour récupérer les clients inscrits entre tel et tel date et qui ont tel âge).
Conceptuellement, voilà la réponse à notre besoin :
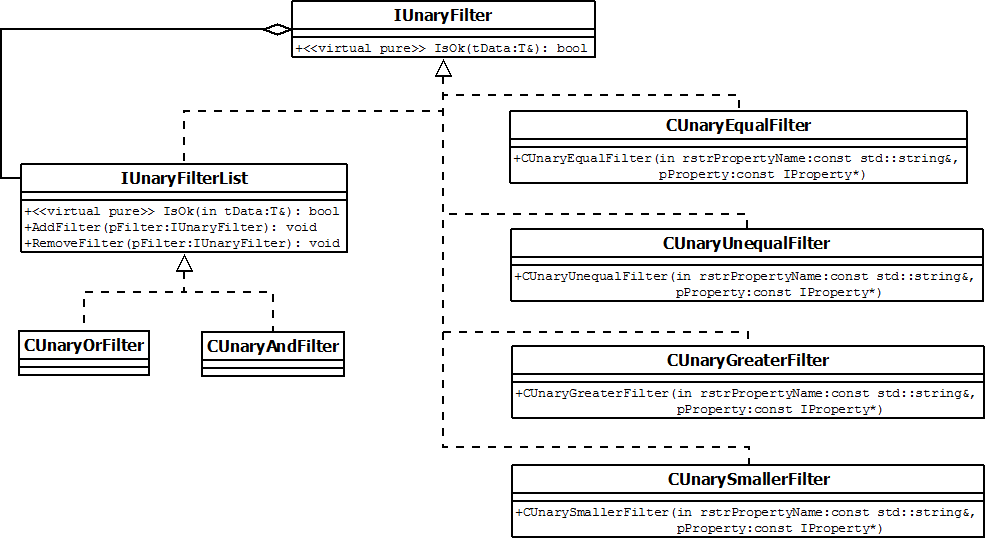
Là nous avons implémenté les opérateurs =, !=, <, et > avec les cumules "OR" et "AND". Voici quelques implémentations :
// L'opérateur =
CUnaryEqualFilter::CUnaryEqualFilter(const std::string& strPropertyName, const IProperty* pProperty)
: m_pProperty(pProperty), m_strPropertyName(strPropertyName)
{
}
bool CUnaryEqualFilter::IsOk(const IData& rData) const
{
return (*(rData.GetProperty(m_strPropertyName))).Compare(*m_pProperty) == 0;
}
// La liste :
void CUnaryFilterList::AddFilter(IUnaryFilter* pFilter)
{
m_vecFilters.push_back(pFilter);
}
void CUnaryFilterList::RemoveFilter(IUnaryFilter* pFilter)
{
m_vecFilters.erase(std::remove(m_vecFilters.begin(), m_vecFilters.end(), pFilter), m_vecFilters.end());
}
// Le AND
bool CUnaryAndFilter::IsOk(const kin::IData& rData) const
{
std::vector<IUnaryFilter*>::const_iterator it = m_vecFilters.begin();
while(it != m_vecFilters.end())
{
if(!(*it)->IsOk(rData))
return false;
++it;
}
return true;
}
// Le OR
bool CUnaryOrFilter::IsOk(const kin::IData& rData) const
{
std::vector<IUnaryFilter*>::const_iterator it = m_vecFilters.begin();
while(it != m_vecFilters.end())
{
if((*it)->IsOk(rData))
return true;
++it;
}
return false;
}
Je vous laisse imaginer le code du reste des opérateurs...
Pour sélectionner les oeuvres entre [1914, 1918] et [1939, 1945] :
CUnaryOrFilter* p1914OrFilter = new CUnaryOrFilter(); // >= 1914
p1914OrFilter->AddFilter(new CUnaryEqualFilter("YEAR", &TUIntProperty(1914)));
p1914OrFilter->AddFilter(new CUnaryGreaterFilter("YEAR", &TUIntProperty(1914)));
CUnaryOrFilter* p1918OrFilter = new CUnaryOrFilter(); // <= 1918
p1918OrFilter->AddFilter(new CUnaryEqualFilter("YEAR", &TUIntProperty(1918)));
p1918OrFilter->AddFilter(new CUnarySmallerFilter("YEAR", &TUIntProperty(1918)));
CUnaryAndFilter* pFirstAndFilter = new CUnaryAndFilter(); // >= 1914 AND <= 1918
pFirstAndFilter->AddFilter(p1914OrFilter);
pFirstAndFilter->AddFilter(p1918OrFilter);
CUnaryOrFilter* p1939OrFilter = new CUnaryOrFilter(); // >= 1939
p1939OrFilter->AddFilter(new CUnaryEqualFilter("YEAR", &TUIntProperty(1939)));
p1939OrFilter->AddFilter(new CUnaryGreaterFilter("YEAR", &TUIntProperty(1939)));
CUnaryOrFilter* p1945OrFilter = new CUnaryOrFilter(); // <= 1945
p1945OrFilter->AddFilter(new CUnaryEqualFilter("YEAR", &TUIntProperty(1945)));
p1945OrFilter->AddFilter(new CUnaryGreaterFilter("YEAR", &TUIntProperty(1945)));
CUnaryAndFilter* pSecondAndFilter = new CUnaryAndFilter(); // >= 1939 AND <= 1945
pFirstAndFilter->AddFilter(p1939OrFilter);
pFirstAndFilter->AddFilter(p1945OrFilter);
CUnaryAndFilter* pFilter = new CUnaryAndFilter(); // (>= 1914 AND <= 1918) OR (>= 1939 AND <= 1945)
pFilter->AddFilter(pFirstAndFilter);
pFilter->AddFilter(pSecondAndFilter);
Ca paraît un peu gros pour effectuer une simple recherche, mais vous n'aurez jamais à avoir à l'écrire comme ça en dur, ou alors pour des petits filtres (quoi que les fonctionnalités de recherches basiques et générales tel que par identifiants seront implémentées séparément).
En général, ce genre de "formule" est issue d'un module de recherche qui la compose de manière générique. Nous allons maintenant câbler ce système à nos gestionnaires.
Pour se faire, nous allons créer un objet, qui se servira d'un filtre afin de se construire une liste de résultat :
template<class T>
class CUnaryQuery
{
friend class CUnaryResultsIterator<T>;
public:
/*!
* \brief Constructeur.
*
* \param poFilter Le filtre utilisé pour effectuer la requête.
*/
CUnaryQuery(IUnaryFilter* poFilter);
/*!
* \brief Lance la requête.
*/
void Query();
private:
IUnaryFilter* m_pFilter; /*!< Le filtre interne. */
typedef std::vector<CData<T>*> TVecResults; /*!< Type de stockage des résultats. */
TVecResults m_vecResults; /*!< Les résultats. */
};
template<class T>
CUnaryQuery<T>::CUnaryQuery(IUnaryFilter* poFilter)
: m_pFilter(poFilter), m_bConnected(false)
{
}
template<class T>
void CUnaryQuery<T>::Query()
{
CDataIterator<T> it; CData<T>* poData = 0;
while((poData = it.GetData()) != 0)
{
if(m_pFilter->IsOk(*poData)) // Donnée trouvée
m_vecResults.push_back(poData); // Nous l'ajoutons aux résultats
ListenData(poData, true); // Nous écoutons toutes les données
it.Next();
}
}Puis un itérateur maison :
/*!
* \brief Itérateur des résultats d'une requête unaire.
*/
template<class T>
class CUnaryResultsIterator
{
public:
/*!
* \brief Constructeur.
*
* \param roQuery La requête dont les résultats seront itérés.
*/
CUnaryResultsIterator(typename CUnaryQuery<T>& roQuery);
/*!
* \brief Obtient le résultat courant.
*
* \return Le résultat courant.
*/
CData<T>* GetData() const;
/*!
* \brief Avance la lecture.
*/
void Next();
private:
typename CUnaryQuery<T>::TVecResults& m_vecResults; /*!< Les résultats sur lesquels itérer. */
typename CUnaryQuery<T>::TVecResults::const_iterator m_iter; /*!< L'itérateur interne. */
};
template<class T>
CUnaryResultsIterator<T>::CUnaryResultsIterator(typename CUnaryQuery<T>& roQuery)
: m_vecResults(roQuery.m_vecResults)
{
roQuery.Query();
m_iter = m_vecResults.begin();
}
template<class T>
CData<T>* CUnaryResultsIterator<T>::GetData() const
{
return m_iter == m_vecResults.end() ? 0 : *m_iter;
}
template<class T>
void CUnaryResultsIterator<T>::Next()
{
++m_iter;
}Et maintenant, l'exécution de la "requête" avec notre filtre précédent :
// Construction puis exécution de la requête "mémoire"
CUnaryQuery<CBook> myQuery(pFilter);
myQuery.Query();
// Puis parcours des résultats
CUnaryResultsIterator<CBook> it(myQuery);
CBook* pData = 0;
while((pData = it.GetData()) != 0)
{
//Résultat courant dans pData
it.Next();
}
En laissant ça comme ça, cela vous permettra de lancer ponctuellement des requêtes. Mais bien souvent, vous aurez besoin de lancer une requête, afficher les résultats, puis rester à jour en fonction des fluctuations des données.
En effet, en reprenant notre filtre en dur de tout à l'heure, vous affichez les livres parus dans les périodes [1914-1918]U[1939-1945].
Admettons que, dans l'IHM de gestion des livres, un nouveau livre est créée... votre interface ne sera plus cohérente avec la réalité des données, où alors le module de création des livres devra communiquer avec le module de consultation, ce qui est conceptuellement incorrect tant la cohésion ne pourra pas être assurée plus haut, et donc le couplage entre les modules augmenté.
Alors, tout comme il est désormais possible d'écouter les fluctuations des livres, nous devons faire en sorte qu'il soit possible d'écouter les fluctuations des résultats d'une recherche de livre.
Pour se faire, notre requête doit écouter le gestionnaire des livres, puis tenir à jour sa liste tout en proposant la notification des fluctuations de ses résultats à quiconque en a besoin.
/*!
* \brief Interface d'écoute d'une requête unaire.
*/
template<class T>
class IQueryListener
{
friend class CUnaryQuery<T>;
protected:
/*!
* \brief Callback appelé lorsqu'un résultat a été ajouté à une requête unaire.
*
* \param poUnaryQuery La requête.
* \param poData Pointeur vers le tableau des éléments qui ont été ajoutés.
* \param ulCount Nombre des éléments ajoutés
*/
virtual void OnQueryResultAdded(CUnaryQuery<T>* poUnaryQuery, CData<T>** poData, unsigned long ulCount) = 0;
/*!
* \brief Callback appelé lorsqu'un résultat a été retiré d'une requête unaire.
*
* \param poUnaryQuery La requête.
* \param poData Pointeur vers le tableau des éléments qui ont été retirés.
* \param ulCount Nombre des éléments retirés
*/
virtual void OnQueryResultRemoved(CUnaryQuery<T>* poUnaryQuery, CData<T>** poData, unsigned long ulCount) = 0;
};
template<class T>
class CUnaryQuery : public IGesDataListener<T>
{
public:
/*!
* \brief Destructeur.
*/
void ~CUnaryQuery()
/*!
* \brief Ajoute un écouteur à cette requête.
*
* \param poListener L'écouteur à ajouter.
*/
void AddListener(IQueryListener<T>* poListener);
/*!
* \brief Retire un écouteur de cette requête.
*
* \param poListener L'écouteur à retirer.
*/
void RemoveListener(IQueryListener<T>* poListener);
private:
/*!
* \brief Callback appelé lorsque des données ont été ajouté dans le gestionnaire.
*
* \param poData pointeur sur le tableau de donnée qui a été ajouté.
* \param ulCount Nombre de données ajoutées.
*/
virtual void OnDataAdded(CData<T>** poData, unsigned long ulCount);
/*!
* \brief Callback appelé lorsque des données ont été retiré dans le gestionnaire.
*
* \param poData pointeur sur le tableau de donnée qui a été ajouté.
* \param ulCount Nombre de données ajoutées.
*/
virtual void OnDataRemoved(CData<T>** poData, unsigned long ulCount);
/*!
* \brief Notifie les écouteurs de cette requête que des résultats ont été ajoutés.
*
* \param poData pointeur sur le tableau de donnée qui a été ajouté.
* \param ulCount Nombre de données ajoutées.
*/
void NotifyQueryResultAdded(CData<T>** poData, unsigned long ulCount);
/*!
* \brief Notifie les écouteurs de cette requête que des résultats ont été retirés.
*
* \param poData pointeur sur le tableau de donnée qui a été retiré.
* \param ulCount Nombre de données retirées.
*/
void NotifyQueryResultRemoved(CData<T>** poData, unsigned long ulCount);
typedef std::vector<IQueryListener<T>*> TVecListeners; /*!< Type de stockage des écouteurs. */
TVecListeners m_vecListeners; /*!< Les écouteurs. */
bool m_bConnected; /*!< Flag interne indiquant si la requête est connectée ou non aux données. */
}
template<class T>
void CUnaryQuery<T>::Query()
{
if(m_bConnected)
return;
// Traitement de la requête
// Nous écoutons le gestionnaire
CGesManager::GetInstance().AddListener<T>(this);
m_bConnected = true;
}
template<class T>
CUnaryQuery<T>::~CUnaryQuery()
{
if(!m_bConnected)
return;
m_pFilter->RemoveListener(this);
}
template<class T>
void CUnaryQuery<T>::AddListener(IQueryListener<T>* poListener)
{
m_vecListeners.push_back(poListener);
}
template<class T>
void CUnaryQuery<T>::RemoveListener(IQueryListener<T>* poListener)
{
m_vecListeners.erase(std::remove(m_vecListeners.begin(), m_vecListeners.end(), poListener), m_vecListeners.end());
}
template<class T>
void CUnaryQuery<T>::NotifyQueryResultAdded(CData<T>** poData, unsigned long ulCount)
{
std::vector<IQueryListener<T>*>::iterator it = m_vecListeners.begin();
while(it != m_vecListeners.end())
{
(*it)->OnQueryResultAdded(this, poData, ulCount);
++it;
}
}
template<class T>
void CUnaryQuery<T>::NotifyQueryResultRemoved(CData<T>** poData, unsigned long ulCount)
{
std::vector<IQueryListener<T>*>::iterator it = m_vecListeners.begin();
while(it != m_vecListeners.end())
{
(*it)->OnQueryResultRemoved(this, poData, ulCount);
++it;
}
}
template<class T>
void CUnaryQuery<T>::OnDataAdded(CData<T>** poData, unsigned long ulCount)
{
// Pour chaque donnée ajoutée, "garder" celles qui correspondent au filtre
std::vector<CData<T>*> vecAddedData; vecAddedData.reserve(ulCount);
for(unsigned long ulIt = 0; ulIt < ulCount; ulIt++)
{
if(m_pFilter->IsOk(*(poData[ulIt])))
{
m_vecResults.push_back(poData[ulIt]);
vecAddedData.push_back(poData[ulIt]);
}
ListenData(poData[ulIt], true); // Puis nous écoutons la donnée
}
NotifyQueryResultAdded(&vecAddedData[0], static_cast<unsigned long>(vecAddedData.size()));
}
template<class T>
void CUnaryQuery<T>::OnDataRemoved(CData<T>** poData, unsigned long ulCount)
{
// pour chaque donnée retirée, dégager celles qui sont stockées ici si elles ne correspondent plus au filtre
std::vector<CData<T>*> vecRemovedData; vecRemovedData.reserve(ulCount);
for(unsigned long ulIt = 0; ulIt < ulCount; ulIt++)
{
std::vector<CData<T>*>::iterator it = std::find(m_vecResults.begin(), m_vecResults.end(), poData[ulIt]);
if(it != m_vecResults.end())
{
m_vecResults.erase(it);
vecRemovedData.push_back(poData[ulIt]);
}
ListenData(poData[ulIt], false);
}
NotifyQueryResultRemoved(&vecRemovedData[0], static_cast<unsigned long>(vecRemovedData.size()));
}
Désormais ceux qui auront besoin de représenter les résultats d'une recherche n'ont plus qu'à se brancher dessus et répondre aux événements reçus.
IV-D. Les connecteurs▲
Donc il nous faut quelque chose entre les sources de données et les gestionnaires. Maintenant nous avons l'habitude, nous allons faire une interface de connecteur, dont les connecteurs concrets hériterons, templarisée selon le type de donnée à gérer. Voici vers quoi nous allons.
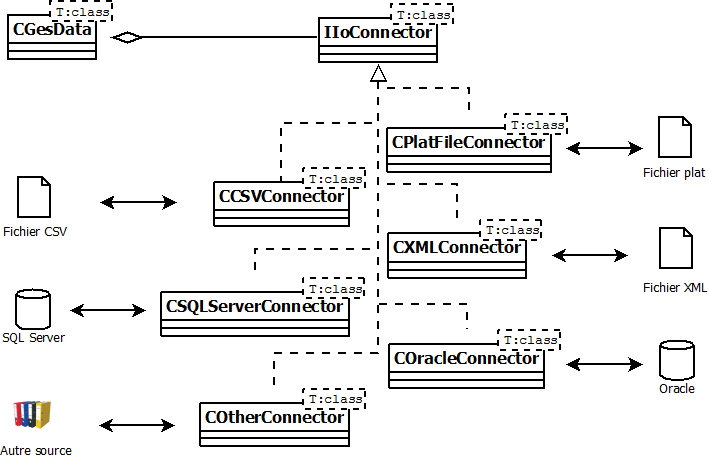
Avant dans se lancer dans la programmation de ces connecteurs, il faut éclaircir deux points
- Quelles méthodes mettre dans l'interface et que devront implémenter les connecteurs ?
- Comment choisir un connecteur plutôt qu'un autre ?
Pour répondre à la première question, nous pouvons utiliser le pattern CRUD. CRUD sont les initiales de "Create", "Read", "Update", "Delete" :
- Create : Crée une donnée dans la source et l'insère au gestionnaire. Pour créer une donnée, nous avons besoin de valeurs. Un dictionnaire entre les propriétés et ces valeurs sera alors passée en paramètre, mais nous pouvons également nous appuyer sur des valeurs par défaut (stockées à la source pour les bases, ou de manière externe pour les fichiers)
- Read : Charge/Met à jour les données mémoire depuis la source. Ici, nous donnerons la possibilité de sélectionner une méthode de chargement ainsi que le remplacement de valeurs. Par exemple, nous n'utiliserons pas la même méthode selon que nous souhaitons charger tous les livres ou bien ceux d'un auteur particulier. Aussi, dans le second cas, il faudra préciser l'identifiant de l'auteur concerné.
- Update : Met à jour les données en base. Cette méthode prendra un tableau de données à mettre à jour (un pointeur sur le premier élément ainsi que le nombre). Un raccourcit pourra être fait pour mettre à jour une seule donnée, ce qui est très fréquent.
- Delete : Supprime la donnée. Pareil qu'au dessus, nous réclamerons les données à supprimer sous forme de tableau avec un raccourcit pour n'en supprimer qu'une.
Le type de connecteur sera sélectionnable, à l'échelle de la donnée (par exemple un fichier XML pour les auteurs, une BDD pour les livres etc.). La configuration de cette sélection sera faîte à l'extérieur, référençant le nom du type de donnée, à l'intérieur. Créons l'interface des connecteurs, templarisée, et branchons là à notre bibliothèque.
/*!
* \brief Classe de base des connecteurs?
*
* \tparam T Le type de donnée à interfacer avec la source.
*/
template<class T>
class IIoConnector
{
public:
/*!
* \brief Destructeur.
*/
virtual ~IIoConnector(){};
/*!
* \brief Crée une donnée.
*
* \param (*pValues) Valeur des propriétés de la donnée à créer.
* \return La donnée nouvellement créée.
*/
virtual CData<T>* Create(std::map<std::string, std::string>* pValues) = 0;
/*!
* \brief Charge les données.
*
* \param usLoadNum Le numéro de chargement.
* \param (*pValues) Les éventuels paramètres de chargement.
*/
virtual void Load() = 0;
/*!
* \brief Met à jour une donnée vers la source.
*
* \param roData La donnée à mettre à jour.
*/
virtual void Update(CData<T>* pData) = 0;
/*!
* \brief Supprime une donnée dans la source.
*
* \param roData La donnée à supprimer.
*/
virtual void Delete(CData<T>* pData) = 0;
protected:
/*!
* \brief Ajoute des données auprès du gestionnaire.
*
* \param ptData Pointeur vers le premier élément des données à ajouter.
* \param ulCount Nombre de donnée à ajouter.
*/
void AddNewData(CData<T>** ptData, unsigned long ulCount);
/*!
* \brief Retire des données auprès du gestionnaire.
*
* \param ptData Pointeur vers le premier élément des données à retirer.
* \param ulCount Nombre de donnée à retirer.
*/
void RemoveData(CData<T>** ptData, unsigned long ulCount);
/*!
* \brief Crée une nouvelle donnée.
*
* \return La donnée.
*/
T* CreateData();
};};
Le principal étant que l'utilisateur n'ait à implémenter que des méthodes spécifiques pour créer et brancher un nouveau connecteur.
Connectons cette interface au gestionnaire de donnée.
template<class T>
class CGesData : public IGesData
{
private:
IIoConnector<T>* m_pIoConnector; /*!< Connecteur de données. */
};Les connecteurs vont créer et supprimer des données dans le gestionnaire. Il n'y a qu'eux qui peuvent le faire. Rappelez vous, les deux méthodes d'ajout et de suppression de données dans le gestionnaire sont privées, nous devons en autoriser l'accès auprès des connecteurs ainsi que des données.
template<class T>
class CGesData : public IGesData
{
friend class IIoConnector<T>;
};
template<class T>
class CData : public IBaseData
{
friend class IIoConnector<T>;
};Imaginez vous chargez 300 000 données... L'utilisateur voudra sûrement proposer une barre de progression. Par conséquent, nous allons ajouter un système d'écoute qui notifiera :
- Le début de chargement, avec le nombre de données à charger
- Le chargement d'une données, avec son index puis rappel du nombre total des données à charger
- La fin du chargement, avec nombre de données chargées
Ainsi, notre écouteur définit, voyons le code :
/*!
* \brief Interface d'écoute des connecteurs IO.
*/
class IIoListener
{
public:
/*!
* \brief Callback appelé lors du début du chargement du connecteur.
*
* \param ulCount Le nombre de données à charger.
*/
virtual void OnBeginLoad(unsigned long ulCount) = 0;
/*!
* \brief Callback appelé lors du chargement d'une donnée.
*
* \param ulCurrent L'index de la donnée en cours de chargement.
* \param ulCount Le nombre de données à charger.
*/
virtual void OnLoading(unsigned long ulCurrent, unsigned long ulCount) = 0;
/*!
* \brief Callback appelé lors de la fin du chargement du connecteur.
*
* \param ulCount Le nombre de données chargées.
*/
virtual void OnEndLoad(unsigned long ulCount) = 0;
};Puis le système d'abonnement/notifications au niveau des connecteurs
template<class T>
class IIoConnector
{
public:
/*!
* \brief Ajoute un écouteur.
*
* \param pListener L'écouteur à ajouter.
*/
void AddListener(IIoListener* pListener);
/*!
* \brief Retire un écouteur.
*
* \param pListener L'écouteur à retirer.
*/
void RemoveListener(IIoListener* pListener);
protected:
/*!
* \brief Notifie un début de chargement.
*
* \param ulCount Le nombre de données total à charger.
*/
void NotifyBeginLoad(unsigned long ulCount);
/*!
* \brief Notifie le chargement d'une donnée.
*
* \param ulCurrent La donnée en cours de chargement.
* \param ulCount Le nombre de données total à charger.
*/
void NotifyLoading(unsigned long ulCurrent, unsigned long ulCount);
/*!
* \brief Notifie un début de chargement.
*
* \param ulCount Le nombre de données qui ont été chargées.
*/
void NotifyEndLoad(unsigned long ulCount);
};
Pas besoin de vous détailler l'algorithmie, vous connaissez.
Pour brancher un écouteur de connecteur, notre développeur passera par GesMgr en précisant le type de donnée dont il souhaite écouter les fluctuations IO. Par conséquent, nous rajoutons les méthodes de branchement Add/Remove au niveau de CGesData puis CGesManager.
Nous allons maintenant créer quelques connecteurs. J'en ai choisi quelques uns pour vous familiariser et créer facilement les vôtres, selon vos format de données spécifiques. Ce que nous implémentons ici sont le CSV, l'XML, le fichier plat et l'ODBC.
IV-D-1. CSV▲
Le format CSV est un format texte, libre qui consiste à séparer les valeurs par des points virgules. Chaque ligne du fichier représente les valeurs d'une donnée, chaque valeur entre les point virgule représente une valeur de propriété de cette donnée. Lorsque la valeur possède un point virgule, celle-ci est entourée de guillemets. Lorsque la valeur possède des guillemets, ceux-ci sont doublés. Il nous faudra un fichier de mapping indiquant quelle "colonne" appartient à quelle propriété. Voici un exemple de fichier CSV pour gérer les livres.
1;Octave est un publicitaire blasé par le monde du maketing qui...;2000;25
2;C++ pour les Nuls;Apprenez efficacement les rouages de C++ dans un...;2006;37
3;Candide;Candide, un jeune homme à la vie heureuse, se voit basculé dans...;1759;14Le fichier de mapping n'a qu'à indiquer, pour chaque type de donnée, le fichier de données ainsi que la propriété correspondante à la position de chaque valeur. Pour ce fichier, nous pouvons indiquer les propriétés dans l'ordre.
<CSV>
<BOOK>
<FILE>Books.csv</FILE>
<PROPERTIES>
<PROPERTY>ID</PROPERTY>
<PROPERTY>TITLE</PROPERTY>
<PROPERTY>DESCRIPTION</PROPERTY>
<PROPERTY>YEAR</PROPERTY>
<PROPERTY>ID_AUTHOR</PROPERTY>
</PROPERTIES>
</BOOK>
<AUTHOR>
<FILE>Author.csv</FILE>
<PROPERTIES>
// propriétés
</PROPERTIES>
</AUTHOR>
</CSV>Maintenant l'importation de ce mapping. Nous utiliserons donc libxml2. D'abord, voyons le stockage des données. Pour chaque entité, nous avons donc une liste de propriété dont il faut conserver l'ordre, un std::vector sera très bien. Et pour lier les entités à leur liste de propriété, nous utiliseront un dictionnaire.
/*!
* \brief Mapping CSV.
*/
class CCSVMapping
{
public:
/*!
* \brief Positionne le fichier de mapping.
*
* \param rstrXml Le fichier XML.
*/
void SetXml(const std::string& rstrXml);
/*!
* \brief Obtient le mapping.
*
* \return Le mapping.
*/
static CCSVMapping& GetMapping();
typedef std::vector<std::string> TVecProperties; /*!< Type de stockage des propriétés. */
/*!
* \brief Obtient les propriétés d'une entité donnée.
*
* \param rstrEntity Le nom de l'entité.
* \return Les propriétés correspondantes.
*/
TVecProperties& GetProperties(const std::string& rstrEntity);
/*!
* \brief Obtient le fichier des données pour une entité.
*
* \param rstrEntity Le nom de l'entité.
* \return Le nom du fichier de données.
*/
const std::string& GetFile(const std::string& rstrEntity);
private:
/*!
* \brief Constructeur.
*/
CCSVMapping();
/*!
* \brief Charge le mapping.
*/
void Load();
/*!
* \brief Structure réunissant le fichier d'un type de données et ses propriétés.
*/
struct SEntityMapping
{
std::string m_strFile;
TVecProperties m_vecProperties;
};
typedef std::map<std::string, SEntityMapping> TMapping; /*!< Type du mapping. */
TMapping m_oMapping; /*!< Stockage du Mapping. */
std::string m_strXml; /*!< Fichier de mapping. */
};
#define CSVMapping CCSVMapping::GetMapping()Intéressons nous juste à la lecture et intégration des données, pour voir un peut l'utilisation de libxml2.
CCSVMapping::CCSVMapping()
: m_strXml("")
{
}
CCSVMapping& CCSVMapping::GetMapping()
{
static CCSVMapping oMapping;
return oMapping;
}
void CCSVMapping::SetXml(const std::string& rstrXml)
{
if(m_strXml != rstrXml)
{
m_strXml = rstrXml;
Load();
}
}
void CCSVMapping::Load()
{
m_oMapping.clear();
if(m_strXml.size() == 0)
return;
xmlDocPtr doc = xmlParseFile(m_strXml.c_str());
if(!doc)
throw CXMLParseException(m_strXml);
xmlNodePtr poFirstChild = doc->children;
if(xmlStrcmp(poFirstChild->name, BAD_CAST("CSV")) != 0)
throw CXMLReadException(m_strXml, reinterpret_cast<const char*>(poFirstChild->name), poFirstChild->line);
xmlNodePtr poEntityNode = poFirstChild->children;
while(poEntityNode)
{
if(poEntityNode->type == XML_TEXT_NODE)
poEntityNode = poEntityNode->next;
if(!poEntityNode)
break;
SEntityMapping& mapping = m_oMapping[reinterpret_cast<const char*>(poEntityNode->name)];
xmlNodePtr poPropertiesNode = poEntityNode->children;
while(poPropertiesNode)
{
if(poPropertiesNode->type == XML_TEXT_NODE)
poPropertiesNode = poPropertiesNode->next;
if(!poPropertiesNode)
break;
if(xmlStrcmp(poPropertiesNode->name, BAD_CAST("PROPERTIES")) == 0)
{
xmlNodePtr poPropertyNode = poPropertiesNode->children;
while(poPropertyNode)
{
if(poPropertyNode->type == XML_TEXT_NODE)
poPropertyNode = poPropertyNode->next;
if(!poPropertyNode)
break;
if(reinterpret_cast<const char*>(poPropertyNode->name) != "PROPERTY")
throw CXMLReadException(m_strXml,
reinterpret_cast<const char*>(poPropertyNode->name),
poPropertyNode->line);
mapping.m_vecProperties.push_back(reinterpret_cast< const char* >(poPropertyNode->children->content));
poPropertyNode = poPropertyNode->next;
}
}
else if(xmlStrcmp(poPropertiesNode->name, BAD_CAST("FILE")) == 0)
{
mapping.m_strFile = reinterpret_cast< const char* >(poPropertiesNode->children->content);
}
else
throw CXMLReadException(m_strXml, reinterpret_cast<const char*>(poPropertiesNode->name), poPropertiesNode->line);
poPropertiesNode = poPropertiesNode->next;
}
poEntityNode = poEntityNode->next;
}
xmlFreeDoc(doc);
}
CCSVMapping::TVecProperties& CCSVMapping::GetProperties(const std::string& rstrEntity)
{
return m_oMapping[rstrEntity].m_vecProperties;
}
const std::string& CCSVMapping::GetFile(const std::string& rstrEntity)
{
return m_oMapping[rstrEntity].m_strFile;
}La méthode est un peu arkaïque mais bon, ça fonctionne bien et la simplicité du fichier XML nous le permet.
Nous ajoutons également un itérateur pour parcourir les propriétés de chaque type de données.
Continuons avec le connecteur. Il implémentera donc l'interface des connecteurs.
/*!
* \brief Le connecteur CSV.
*
* \tparam T Le type de donnée à interfacer avec la source.
*/
template<class T>
class CCSVConnector : public IIoConnector<T>
{
friend class CIoFactory;
public:
/*!
* \brief Obtient le fichier de données.
*
* \return Le fichier de données.
*/
const std::string& GetDataFile();
protected:
/*!
* \brief Crée une donnée.
*
* \param (*pValues) Valeur des propriétés de la donnée à créer.
* \return La donnée nouvellement créée.
*/
virtual CData<T>* Create(std::map<std::string, std::string>* pValues);
/*!
* \brief Charge les données.
*
* \param usLoadNum Le numéro de chargement.
* \param (*pValues) Les éventuels paramètres de chargement.
*/
virtual void Load();
/*!
* \brief Met à jour une donnée vers la source.
*
* \param roData La donnée à mettre à jour.
*/
virtual void Update(CData<T>* pData);
/*!
* \brief Supprime une donnée dans la source.
*
* \param roData La donnée à supprimer.
*/
virtual void Delete(CData<T>* pData);
/*!
* \brief Crée un nouvel identifiant pour ce type de donnée.
*
* \return Le nouvel identifiant.
*/
virtual TUInt64Property GetNewIdent();
private:
/*!
* \brief Constructeur interdit, uniquement créé par la fabrique.
*/
CCSVConnector(){};
/*!
* \brief Lit une ligne du fichier pour remplir une donnée.
*
* \param oFile Le fichier à lire.
* \param roData La donnée à remplir.
* \return true si le traitement s'est bien passé, sinon false.
*/
bool ReadLine(std::fstream& oFile, CData<T>& roData);
/*!
* \brief Remplir une donnée à partir d'une chaîne (ligne).
*
* \param strLine La ligne.
* \param roData La donnée à remplir.
*/
void ReadLine(std::string& strLine, CData<T>& roData);
/*!
* \brief Convertit une donnée en ligne CSV.
*
* \param roData La donnée à convertir.
* \return La ligne.
*/
std::string ToLine(CData<T>& roData);
/*!
* \brief Formatte une chaîne au format CSV.
*
* \param rstrValue La chaîne à formatter.
* \return La chaîne formatté.
*/
std::string FormatToExport(const std::string& rstrValue);
/*!
* \brief Retire le format CSV d'une chaîne.
*
* \param rstrValue La chaîne formattée.
* \return La chaîne sans format.
*/
std::string FormatToImport(const std::string& rstrValue);
std::string m_strDataFile; /*!< Le fichier des données T. */
};
template<class T>
const std::string& CCSVConnector<T>::GetDataFile()
{
if(m_strDataFile.size() == 0)
m_strDataFile = CSVMapping.GetFile(SDataTrait<T>::CODE);
return m_strDataFile;
}
template<class T>
std::string CCSVConnector<T>::FormatToExport(const std::string& rstrValue)
{
std::string strValue = rstrValue;
if(strValue.find_first_of(';') != std::string::npos)
{
strValue = Replace(strValue, "\"", "\"\"");
strValue = "\"" + strValue + "\"";
}
return strValue;
}
template<class T>
std::string CCSVConnector<T>::FormatToImport(const std::string& rstrValue)
{
if(rstrValue.size() < 2)
return rstrValue;
if(rstrValue[0] == '"' && rstrValue[rstrValue.size() - 1] == '"')
return Replace(rstrValue.substr(1, rstrValue.size() - 2), "\"\"", "\"");
return rstrValue;
}
template<class T>
bool CCSVConnector<T>::ReadLine(std::fstream& oFile, CData<T>& roData)
{
std::string strLine;
if(!std::getline(oFile, strLine))
{
oFile.clear();
return false;
}
if(strLine.size() > 0)
{
ReadLine(strLine, roData);
}
return true;
}
template<class T>
std::string CCSVConnector<T>::ToLine(CData<T>& roData)
{
std::string strLine = "";
CCSVMappingIterator<T> iter;
while(iter.HasNext())
{
const std::string& rstrPropertyName = iter.GetPropertyName();
std::string strValue = roData.GetProperty(rstrPropertyName)->ToString();
strValue = FormatToExport(strValue);
if(!iter.IsFirst())
strLine += ";";
strLine += strValue;
iter.Next();
}
return strLine;
}Maintenant intéressons nous aux quatre méthodes de manipulation de la source de données.
IV-D-1-1. Create▲
Cette méthode prend donc en paramètre les paires noms de propriétés / valeurs, sous forme de chaînes de caractère. Le premier travail de la fonction de création est de s'assurer qu'aucune donnée portant les mêmes identifiants n'existe à l'issue de quoi une exception sera levée. Dans le cas contraire, une nouvelle donnée sera alors créée, puis remplie avec les valeurs passées en paramètre et enfin ajouté à la source avant d'être stockée dans le gestionnaire.
template<class T>
CData<T>* CCSVConnector<T>::Create(std::map<std::string, std::string>* pValues)
{
std::fstream oFile;
oFile.open(GetDataFile().c_str(), std::ios_base::app);
if(!oFile)
throw CFileAccessException(GetDataFile());
// TODO : Chercher à la source
CData<T>* tData = CGesManager::GetInstance().GetFromIdentsStr<T>(*pValues);
if(tData)
throw CDataAlreadyExistsException<T>(*tData);
tData = CreateData();
std::string strLine;
CCSVMappingIterator<T> iter;
while(iter.HasNext())
{
const std::string& rstrPropertyName = iter.GetPropertyName();
std::string strValue = (*pValues)[rstrPropertyName];
try
{
tData->GetProperty(rstrPropertyName)->FromString(strValue);
}
catch(CException& excep)
{
delete tData;
throw CCreateDataException(
SDataTrait<T>::CODE,
rstrPropertyName,
strValue,
&excep);
}
strValue = FormatToExport(strValue);
if(!iter.IsFirst())
strLine += ";";
strLine += strValue;
iter.Next();
}
oFile << strLine << std::endl;
oFile.close();
AddNewData(&tData, 1);
return tData;
}IV-D-1-2. Load▲
La méthode de chargement va lire le fichier du début à la fin. Au début du chargement, nous recopierons les données déjà présentes dans le gestionnaire afin qu'à chaque donnée lue, nous puissions chercher si la donnée existe déjà en mémoire ou s'il faut la créer. Les recopies de pointeurs permettent d'éviter de tester leur existence avec les données précédemment lues dans la même phase de chargement. Enfin, les données créées seront envoyées au gestionnaire afin d'être référencées.
template<class T>
void CCSVConnector<T>::Load()
{
std::fstream oFile;
oFile.open(GetDataFile().c_str(), std::ios_base::in);
if(!oFile)
throw CFileAccessException(GetDataFile());
std::vector<CData<T>*> vecAlreadyExistsData;
vecAlreadyExistsData.reserve(CGesManager::GetInstance().GetCount<T>());
CDataIterator<T> dataIter; CData<T>* tExistsData = 0;
while((tExistsData = dataIter.GetData()) != 0)
{
vecAlreadyExistsData.push_back(tExistsData);
dataIter.Next();
}
std::vector<CData<T>*> vecNewDatas;
vecNewDatas.reserve(std::count(std::istreambuf_iterator<char>(oFile),
std::istreambuf_iterator<char>(), '\n'));
T& tTempData = T::GetModel();
oFile.seekg(std::ios::beg);
while(ReadLine(oFile, tTempData))
{
bool bNew = true;
std::vector<CData<T>*>::iterator existsIt = vecAlreadyExistsData.begin();
while(existsIt != vecAlreadyExistsData.end())
{
if((*existsIt)->IsSame(tTempData))
{
(*existsIt)->CopyFrom(tTempData); // Mise à jour
bNew = false;
}
++existsIt;
}
if(bNew)
{
CData<T>* poData = CreateData();
poData->CopyFrom(tTempData);
vecNewDatas.push_back(poData);
}
}
oFile.close();
if(vecNewDatas.size() > 0)
AddNewData(&vecNewDatas[0], static_cast<unsigned long>(vecNewDatas.size()));
}IV-D-1-3. Update▲
Cette méthode va commencer par chercher la ligne de la donnée, puis la mettre à jour depuis les valeurs mémoire.
template<class T>
void CCSVConnector<T>::Update(CData<T>* pData)
{
std::fstream oFile;
oFile.open(GetDataFile().c_str(), std::ios_base::in);
if(!oFile)
throw CFileAccessException(GetDataFile());
T& tTempData = T::GetModel();
std::vector<std::string> strValues;
strValues.reserve(std::count(std::istreambuf_iterator<char>(oFile),
std::istreambuf_iterator<char>(), '\n'));
oFile.seekg(std::ios::beg);
bool bFound = false;
std::string str;
while(std::getline(oFile, str))
{
ReadLine(str, tTempData);
if(!bFound && tTempData.IsSame(*pData))
{
bFound = true;
strValues.push_back(ToLine(*pData));
}
else
strValues.push_back(str);
}
oFile.close();
bool b = oFile.is_open();
oFile.clear();
oFile.open(GetDataFile().c_str(), std::ios_base::out);
if(!oFile)
throw CFileAccessException(GetDataFile());
std::vector<std::string>::iterator itLines = strValues.begin();
while(itLines != strValues.end())
{
oFile << *itLines << std::endl;
++itLines;
}
oFile.close();
}IV-D-1-4. Delete▲
Cette méthode va commencer par chercher la ligne de la donnée, puis la mettre à jour depuis les valeurs mémoire.
template<class T>
void CCSVConnector<T>::Delete(CData<T>* pData)
{
std::fstream oFile;
oFile.open(GetDataFile().c_str(), std::ios_base::in);
if(!oFile)
throw CFileAccessException(GetDataFile());
T& tTempData = T::GetModel();
std::vector<std::string> strValues;
strValues.reserve(std::count(std::istreambuf_iterator<char>(oFile),
std::istreambuf_iterator<char>(), '\n'));
oFile.seekg(std::ios::beg);
bool bFound = false;
std::string str;
while(std::getline(oFile, str))
{
ReadLine(str, tTempData);
if(!bFound && tTempData.IsSame(*pData))
bFound = true;
else
strValues.push_back(str);
}
oFile.close();
oFile.clear();
oFile.open(GetDataFile().c_str(), std::ios_base::out);
if(!oFile)
throw CFileAccessException(GetDataFile());
std::vector<std::string>::iterator itLines = strValues.begin();
while(itLines != strValues.end())
{
oFile << *itLines << std::endl;
++itLines;
}
oFile.close();
RemoveData(&pData, 1);
}IV-D-2. XML▲
Passons maintenant au format XML et comme pour le format CSV, commençons par le mapping. Il aura cette forme :
<XML>
<BOOK>
<NODES>
<NODE>
<NODE>ident</NODE>
<PROPERTY>ID</PROPERTY>
</NODE>
<NODE>
<NODE>titre</NODE>
<PROPERTY>TITLE</PROPERTY>
</NODE>
<NODE>
<NODE>description</NODE>
<PROPERTY>DESCRIPTION</PROPERTY>
</NODE>
<NODE>
<NODE>year</NODE>
<PROPERTY>YEAR</PROPERTY>
</NODE>
<NODE>
<NODE>autheur</NODE>
<PROPERTY>ID_AUTHOR</PROPERTY>
</NODE>
</NODES>
</BOOK>
<AUTHOR>
// Mapping noeud/propriétés
</AUTHOR>
</XML>
J'ai choisit ce style de format pour mettre en valeur de côté découplé du reste, mais vous pouvez en choisir un autre privilégiant la taille du fichier ou la rapidité de lecture/écriture.
Quand à notre fichier de données, il ressemblera à ceci :
<XMLDATA>
<DATA>
<ident>1</ident>
<titre>99 francs (14,99€)</titre>
<description>Octave est un publicitaire blasé par le monde du maketing qui...</description>
<year>2000</year>
<autheur>25</autheur>
</DATA>
<DATA>
<ident>2</ident>
<titre>C++ pour les Nuls</titre>
<description>Apprenez efficacement les rouages de C++ dans un...</description>
<year>2006</year>
<autheur>37</autheur>
</DATA>
<DATA>
<ident>3</ident>
<titre>Candide</titre>
<description>Candide, un jeune homme à la vie heureuse, se voit basculé dans...</description>
<year>1759</year>
<autheur>14</autheur>
</DATA>
</XMLDATA>C'est parti pour le mapping. La structure des données mémoires va être un peu exotique, mais plus simple que ça n'y paraît. En effet, hormis le stockage des données, nous voudront inscrire les propriétés de chaque donnée dans le même ordre que ce qui est fait dans le mapping. Pourquoi ? Pour un soucis de lisibilité, nous imaginons bien l'utilisateur, en Debug, chercher sa donnée dans le fichier, puis ensuite chercher la propriété qui l'intéresse. C'est donc non négligeable de respecter un ordre, à force, il saura que telle propriété se trouve plutôt au milieu qu'à la fin (imaginez que dans vos bases de données quelqu'un modifie l'ordre des champs...). Donc il va falloir trier par ordre d'insertion des données. Aussi, au chargement, nous auront besoin d'obtenir un nom de propriété via un nom de noeud XML, et à la sauvegarde, retrouver le nouds via la propriété, donc il faut un mapping dans l'autre sens. Un truc de ***** serait d'agir ainsi :
private:
std::map<std::string, std::string> m_oMapPropertiesToNodes; // Map des propriétés vers les noeuds
std::map<std::string, std::string> m_oMapNodesToProperties; // Map des noeuds vers les propriétés
std::vector<std::string> m_vecProperties; // Liste des propriétés, dans l'ordre du mapping
std::vector<std::string> m_vecNodes; // Liste des noeuds, dans l'ordre du mapping
Voilà une solution, à priori simple mais... essayez de la gérer, tant au chargement qu'à l'utilisation, et la lourdeur du code ainsi que les différents problèmes vous calmeront rapidement. Faisons autrement : nous devons gérer des couples noeuds/propriétés, et y accéder de différentes manières, comme si nous avions une structure liant les deux valeurs, une liste stockant ces couples puis plusieurs index pour manipuler cette liste. Il nous faut une liste à plusieurs index, ou multi index, ou bien multi_index, ou plus précisément boost::multi_index :)
Boost nous offre cette possibilité, voyons voir ça :
private:
/*!
* \brief Structure de regroupement d'un nom de propriété/nom de noeud.
*/
struct SNode
{
std::string m_strNodeName; /*!< Le nom du noeud. */
std::string m_strPropertyName; /*!< Le nom de la propriété. */
};
/*!
* \brief Identifiant de l'index d'ordonnancement par insertion.
*/
struct SOrderedAsInserted{};
/*!
* \brief Identifiant de l'index d'ordonnancement par noeud.
*/
struct SOrderedAsNodes{};
/*!
* \brief Identifiant de l'index d'ordonnancement par propriété.
*/
struct SOrderedAsProperties{};
typedef boost::multi_index::multi_index_container<SNode, // container de nodes
boost::multi_index::indexed_by< // indexé par
boost::multi_index::sequenced<boost::multi_index::tag<SOrderedAsInserted>>, // insertion
boost::multi_index::ordered_unique< // noeuds
boost::multi_index::tag<SOrderedAsNodes>,
boost::multi_index::member<SNode,std::string,&SNode::m_strNodeName>>,
boost::multi_index::ordered_unique< // propriété
boost::multi_index::tag<SOrderedAsProperties>,
boost::multi_index::member<SNode,std::string,&SNode::m_strPropertyName>>
>
> TMappingSet; /*!< Type du mapping par entité. */
// Quelques racourcit pour accéder aux index
typedef TMappingSet::index<SOrderedAsInserted>::type TMappingByInsertion; /*!< Type de l'index par insertion. */
typedef TMappingSet::index<SOrderedAsNodes>::type TMappingByNodes; /*!< Type de l'index sur les noeuds. */
typedef TMappingSet::index<SOrderedAsProperties>::type TMappingByProperties; /*!< Type de l'index sur les propriétés. */
/*!
* \brief Structure liant le fichier de données et le mapping des propriétés pour un type d'entité.
*/
struct SEntityMapping
{
std::string m_strFile; /*!< Le fichier. */
TMappingSet m_oMapping; /*!< Le mapping.*/
};
typedef std::map<std::string, SEntityMapping> TMapping; /*!< Type du mapping complet. */
TMapping m_oMapping; /*!< Le mapping. */Le reste est similaire au connecteur CSV, c'est pourquoi je ne vais pas le répéter ici. En revanche, intéressons nous au stockage des données puis leur exploitation.
// insertion
SNode node;
node.m_strNodeName = [nom du noeud];
node.m_strPropertyName = [nom de la propriété];
m_oMapping[CBaseTrait<T>::CODE].insert(mapNodes.end(), newNode);
// recherche d'un noeud selon une propriété (utilisé pour la sauvegarde)
const std::string& CXmlMapping::GetNodeByProperty(const std::string& rstrEntity, const std::string& rstrPropertyName)
{
return (*(m_oMapping[rstrEntity].m_oMapping.get<SOrderedAsProperties>().find(rstrPropertyName))).m_strNodeName;
}
// recherche d'une propriété selon un noeud (utilisé pour le chargement des données)
const std::string& CXmlMapping::GetPropertyByNode(const std::string& rstrEntity, const std::string& strNodeName)
{
return (*(m_oMapping[rstrEntity].m_oMapping.get<SOrderedAsNodes>().find(strNodeName))).m_strPropertyName;
}
// Récupération de la liste des noeuds, prête à être parcourue par un itérateur.
CXmlMapping::TMappingByInsertion& CXmlMapping::GetNodes(const std::string& rstrEntity)
{
return m_oMapping[rstrEntity].m_oMapping.get<SOrderedAsInserted>();
}
const std::string& CXmlMapping::GetFile(const std::string& rstrEntity)
{
return m_oMapping[rstrEntity].m_strFile;
}
// Le TMappingByInsertion est utilisable comme un vector par exemple (iterator, begin, end etc...),
// par conséquent, l'itérateur sera similaire aux autres.Voilà pour l'aspect technique de ce mapping, le reste étant similaire au mapping du CSV, vous le trouverez dans les sources à télécharger, y compris l'itérateur maison qui va avec.
IV-D-2-1. Create▲
template<class T>
CData<T>* CXmlConnector<T>::Create(std::map<std::string, std::string>* pValues)
{ // Faut regarder dans la source si ça existe, et non pas en mémoire
xmlNodePtr newNode = xmlNewChild(xmlDocGetRootElement(m_pDoc), 0, BAD_CAST("DATA"), 0);
CData<T>* tData = CGesManager::GetInstance().GetFromIdentsStr<T>(*pValues);
if(tData)
throw CDataAlreadyExistsException<T>(*tData);
tData = CreateData();
CXmlMappingIterator<T> iter;
while(iter.HasNext())
{
const std::string strPropertyName = iter.GetPropertyName();
const std::string strValue = (*pValues)[strPropertyName];
xmlNodePtr newChild = xmlNewChild(newNode, 0, BAD_CAST(iter.GetNodeName().c_str()), BAD_CAST(strValue.c_str()));
try
{
tData->GetProperty(iter.GetPropertyName())->FromString(strValue);
}
catch(CException& excep)
{
delete tData;
throw CCreateDataException(
SDataTrait<T>::CODE,
strPropertyName,
strValue,
&excep);
}
iter.Next();
}
Save();
AddNewData(&tData, 1);
return tData;
}IV-D-2-2. Load▲
template<class T>
void CXmlConnector<T>::Load()
{
xmlXPathContextPtr ctxt = xmlXPathNewContext(m_pDoc);
xmlXPathObjectPtr obj = xmlXPathEvalExpression(BAD_CAST("count(//DATA)"), ctxt);
long lCount = static_cast<long>(xmlXPathCastToNumber(obj));
std::vector<CData<T>*> vecAlreadyExistsData;
vecAlreadyExistsData.reserve(CGesManager::GetInstance().GetCount<T>());
CDataIterator<T> dataIter; CData<T>* tExistsData = 0;
while((tExistsData = dataIter.GetData()) != 0)
{
vecAlreadyExistsData.push_back(tExistsData);
dataIter.Next();
}
xmlNodePtr oNode = m_pDoc->children;
std::vector<CData<T>*> vecNewDatas;
vecNewDatas.reserve(lCount);
while(oNode != 0)
{
if(oNode->type == XML_TEXT_NODE)
oNode = oNode->next;
if(!oNode)
break;
if(xmlStrcmp(oNode->name, BAD_CAST("XMLDATA")) == 0)
{
xmlNodePtr oDataNode = oNode->children;
while(oDataNode != 0)
{
if(oDataNode->type == XML_TEXT_NODE)
oDataNode = oDataNode->next;
if(!oDataNode)
break;
if(xmlStrcmp(oDataNode->name, BAD_CAST("DATA")) == 0)
{
T& tTempData = CData<T>::GetModel();
xmlNodePtr oChild = oDataNode->children;
while(oChild != 0)
{
if(oChild->type == XML_TEXT_NODE)
oChild = oChild->next;
if(!oChild)
break;
std::string strNodeName = (const char*)oChild->name;
std::string strPropertyName = XMLMapping.GetPropertyByNode(SDataTrait<T>::CODE, strNodeName);
tTempData.GetProperty(strPropertyName)->FromString((const char*)oChild->children->content);
oChild = oChild->next;
}
bool bNew = true;
std::vector<CData<T>*>::iterator existsIt = vecAlreadyExistsData.begin();
while(existsIt != vecAlreadyExistsData.end())
{
if((*existsIt)->IsSame(tTempData))
{
(*existsIt)->CopyFrom(tTempData); // Mise à jour
bNew = false;
}
++existsIt;
}
if(bNew)
{
CData<T>* poData = CreateData();
poData->CopyFrom(tTempData);
vecNewDatas.push_back(poData);
}
}
oDataNode = oDataNode->next;
}
}
oNode = oNode->next;
}
if(vecNewDatas.size() > 0)
AddNewData(&vecNewDatas[0], static_cast<unsigned long>(vecNewDatas.size()));
}IV-D-2-3. Update▲
template<class T>
void CXmlConnector<T>::Update(CData<T>* pData)
{
// Nous recherchons la donnée dans l'xml
std::string strXmlPathQuerie = "";
CDataIdentIterator<T> identIt;
while(identIt.HasNext())
{
strXmlPathQuerie += strXmlPathQuerie.size() == 0 ? "" : " AND ";
strXmlPathQuerie += XMLMapping.GetNodeByProperty(SDataTrait<T>::CODE, identIt.GetIdentName());
strXmlPathQuerie += " = '" + pData->GetProperty(identIt.GetIdentName())->ToString() + "'";
identIt.Next();
}
strXmlPathQuerie = "/XMLDATA/DATA[" + strXmlPathQuerie + "]";
xmlXPathContextPtr ctxt = xmlXPathNewContext(m_pDoc);
xmlXPathObjectPtr obj = xmlXPathEvalExpression(BAD_CAST(strXmlPathQuerie.c_str()), ctxt);
xmlNodePtr nodeToUpdate = obj->nodesetval->nodeTab[0];
if(!nodeToUpdate)
return;
ctxt->node = nodeToUpdate;
CXmlMappingIterator<T> mapIt;
while(mapIt.HasNext())
{
std::string strNodeName = mapIt.GetNodeName();
xmlNodePtr node = nodeToUpdate->children;
while(node != 0)
{
if(node->type == XML_TEXT_NODE)
node = node->next;
if(!node)
xmlNewChild(nodeToUpdate,
0,
BAD_CAST(strNodeName.c_str()),
BAD_CAST(pData->GetProperty(mapIt.GetPropertyName())->ToString().c_str()));
else
{
if(xmlStrcmp(node->name, BAD_CAST(strNodeName.c_str())) == 0)
{
xmlNodeSetContent(node,
BAD_CAST(
pData->GetProperty(mapIt.GetPropertyName())->ToString().c_str()));
break;
}
}
if(!node->next)
xmlNewChild(nodeToUpdate,
0,
BAD_CAST(strNodeName.c_str()),
BAD_CAST(pData->GetProperty(mapIt.GetPropertyName())->ToString().c_str()));
node = node->next;
}
mapIt.Next();
}
Save();
}IV-D-2-4. Delete▲
template<class T>
void CXmlConnector<T>::Delete(CData<T>* pData)
{
// Nous recherchons la donnée dans l'xml
std::string strXmlPathQuerie = "";
CDataIdentIterator<T> identIt;
while(identIt.HasNext())
{
strXmlPathQuerie += strXmlPathQuerie.size() == 0 ? "" : " AND ";
strXmlPathQuerie += XMLMapping.GetNodeByProperty(SDataTrait<T>::CODE, identIt.GetIdentName());
strXmlPathQuerie += " = '" + pData->GetProperty(identIt.GetIdentName())->ToString() + "'";
identIt.Next();
}
strXmlPathQuerie = "/XMLDATA/DATA[" + strXmlPathQuerie + "]";
xmlXPathContextPtr ctxt = xmlXPathNewContext(m_pDoc);
xmlXPathObjectPtr obj = xmlXPathEvalExpression(BAD_CAST(strXmlPathQuerie.c_str()), ctxt);
xmlNodePtr nodeToDelete = obj->nodesetval->nodeTab[0];
if(!nodeToDelete)
return;
xmlUnlinkNode(nodeToDelete);
Save();
RemoveData(&pData, 1);
}IV-D-3. Fichier plat▲
Le fichier plat possède, comme le format CSV, une ligne par donnée. En revanche, chaque champ possède une taille limite. Voyons un exemple :
1 99 francs (14,99€) Octave est un publicitaire blasé par le monde du maketing qui... 200025
2 C++ pour les Nuls Apprenez efficacement les rouages de C++ dans un... 200637
3 Candide Candide, un jeune homme à la vie heureuse, se voit basculé dans... 175914Dans cet exemple, j'ai posé la taille de l'identifiant à 6 chiffres max, le titre à 30 caractère max, la description 100, l'année 4 et l'identifiant de l'auteur 6.
Concernant le mapping, il devra alors spécifier chaque propriété ainsi que la taille qu'elle occupe dans le fichier.
<PLATFILE>
<BOOK>
<FILE>Books.txt</FILE>
<PROPERTIES>
<PROPERTY>
<PROPERTY>ID</PROPERTY>
<SIZE>6</SIZE>
</PROPERTY>
<PROPERTY>
<PROPERTY>TITLE</PROPERTY>
<SIZE>30</SIZE>
</PROPERTY>
<PROPERTY>
<PROPERTY>DESCRIPTION</PROPERTY>
<SIZE>150</SIZE>
</PROPERTY>
<PROPERTY>
<PROPERTY>YEAR</PROPERTY>
<SIZE>4</SIZE>
</PROPERTY>
<PROPERTY>
<PROPERTY>ID_EDITOR</PROPERTY>
<SIZE>6</SIZE>
</PROPERTY>
<PROPERTY>
<PROPERTY>ID_AUTHOR</PROPERTY>
<SIZE>6</SIZE>
</PROPERTY>
</PROPERTIES>
</BOOK>
<AUTHOR>
...
</AUTHOR>
</PLATFILE>Ce qui en terme de structure de stockage du mapping, nous amène à ceci :
/*!
* \brief Structure de regroupement d'un nom de propriété avec sa taille.
*/
struct SData
{
std::string m_strPropertyName; /*!< Le nom de la propriété. */
unsigned int m_uiSize; /*!< Sa taille dans le fichier. */
};
/*!
* \brief Identifiant de l'index d'ordonnancement par insertion.
*/
struct SOrderedAsInserted{};
/*!
* \brief Identifiant de l'index d'ordonnancement par propriété.
*/
struct SOrderedAsProperties{};
typedef boost::multi_index::multi_index_container<SData, // container de nodes
boost::multi_index::indexed_by< // indexé par
boost::multi_index::sequenced<boost::multi_index::tag<SOrderedAsInserted>>, // insertion
boost::multi_index::ordered_unique< // propriétés
boost::multi_index::tag<SOrderedAsProperties>,
boost::multi_index::member<SData,std::string,&SData::m_strPropertyName>>
>
> TMappingSet; /*!< Type du mapping par entité. */
typedef TMappingSet::index<SOrderedAsInserted>::type TMappingByInsertion; /*!< Type de l'index par insertion. */
typedef TMappingSet::index<SOrderedAsProperties>::type TMappingByProperties; /*!< Type de l'index sur les propriétés. */
/*!
* \brief Structure liant le fichier et le mapping des propriétés pour un type d'entité.
*/
struct SEntityMapping
{
std::string m_strFile; /*!< Le fichier. */
TMappingSet m_oMapping; /*!< Le mapping.*/
};
typedef std::map<std::string, SEntityMapping> TMapping; /*!< Type du mapping complet. */
TMapping m_oMapping; /*!< Le mapping. */La structure du connecteur est la même que les autres, c'est pourquoi nous passons directement à l'algorithmie.
IV-D-3-1. Create▲
template<class T>
CData<T>* CPlatFileConnector<T>::Create(std::map<std::string, std::string>* pValues)
{
std::fstream oFile;
oFile.open(m_strDataFile.c_str(), std::ios_base::app);
if(!oFile)
throw CFileAccessException(m_strDataFile);
// TODO : Chercher à la source
CData<T>* tData = CGesManager::GetInstance().GetFromIdentsStr<T>((*pValues));
if(tData)
throw CDataAlreadyExistsException<T>(*tData);
tData = CreateData();
std::ostringstream oLineStream;
CPlatFileMappingIterator<T> iter;
while(iter.HasNext())
{
const std::string& rstrPropertyName = iter.GetPropertyName();
std::string strValue = (*pValues)[rstrPropertyName];
try
{
tData->GetProperty(rstrPropertyName)->FromString(strValue);
}
catch(CException& excep)
{
delete tData;
throw CCreateDataException(
SDataTrait<T>::CODE,
rstrPropertyName,
strValue,
&excep);
}
oLineStream << std::left << std::setw(iter.GetPropertySize()) << strValue;
iter.Next();
}
oFile << oLineStream.str() << std::endl;
oFile.close();
AddNewData(&tData, 1);
return tData;
}IV-D-3-2. Load▲
template<class T>
void CPlatFileConnector<T>::Load()
{
std::fstream oFile;
oFile.open(m_strDataFile.c_str(), std::ios_base::in);
if(!oFile)
throw CFileAccessException(m_strDataFile);
std::vector<CData<T>*> vecAlreadyExistsData;
vecAlreadyExistsData.reserve(CGesManager::GetInstance().GetCount<T>());
CDataIterator<T> dataIter; CData<T>* tExistsData = 0;
while((tExistsData = dataIter.GetData()) != 0)
{
vecAlreadyExistsData.push_back(tExistsData);
dataIter.Next();
}
std::vector<CData<T>*> vecNewDatas;
vecNewDatas.reserve(std::count(std::istreambuf_iterator<char>(oFile),
std::istreambuf_iterator<char>(), '\n'));
T* pTempData = CreateData();
oFile.seekg(std::ios::beg);
while(ReadLine(oFile, *pTempData))
{
bool bNew = true;
std::vector<CData<T>*>::iterator existsIt = vecAlreadyExistsData.begin();
while(existsIt != vecAlreadyExistsData.end())
{
if((*existsIt)->IsSame(*pTempData))
{
(*existsIt)->CopyFrom(*pTempData); // Mise à jour
bNew = false;
}
++existsIt;
}
if(bNew)
vecNewDatas.push_back(pTempData);
else
delete pTempData;
}
oFile.close();
if(vecNewDatas.size() > 0)
AddNewData(&vecNewDatas[0], static_cast<unsigned long>(vecNewDatas.size()));
}IV-D-3-3. Update▲
template<class T>
void CPlatFileConnector<T>::Update(CData<T>* pData)
{
std::fstream oFile;
oFile.open(m_strDataFile.c_str(), std::ios_base::in);
if(!oFile)
throw CFileAccessException(m_strDataFile);
T& tTempData = T::GetModel();
std::vector<std::string> strValues;
strValues.reserve(std::count(std::istreambuf_iterator<char>(oFile),
std::istreambuf_iterator<char>(), '\n'));
oFile.seekg(std::ios::beg);
bool bFound = false;
std::string str;
while(std::getline(oFile, str))
{
ReadLine(str, tTempData);
if(!bFound && tTempData.IsSame(*pData))
{
bFound = true;
strValues.push_back(ToLine(*pData));
}
else
strValues.push_back(str);
}
oFile.close();
oFile.clear();
oFile.open(m_strDataFile.c_str(), std::ios_base::out);
if(!oFile)
throw CFileAccessException(m_strDataFile);
std::vector<std::string>::iterator itLines = strValues.begin();
while(itLines != strValues.end())
{
oFile << *itLines << std::endl;
++itLines;
}
oFile.close();
}IV-D-3-4. Delete▲
template<class T>
void CPlatFileConnector<T>::Delete(CData<T>* pData)
{
std::fstream oFile;
oFile.open(m_strDataFile.c_str(), std::ios_base::in);
if(!oFile)
throw CFileAccessException(m_strDataFile);
T& tTempData = T::GetModel();
std::vector<std::string> strValues;
strValues.reserve(std::count(std::istreambuf_iterator<char>(oFile),
std::istreambuf_iterator<char>(), '\n'));
oFile.seekg(std::ios::beg);
bool bFound = false;
std::string str;
while(std::getline(oFile, str))
{
ReadLine(str, tTempData);
if(!bFound && tTempData.IsSame(*pData))
bFound = true;
else
strValues.push_back(str);
}
oFile.close();
bool b = oFile.is_open();
oFile.clear();
oFile.open(m_strDataFile.c_str(), std::ios_base::out);
if(!oFile)
throw CFileAccessException(m_strDataFile);
std::vector<std::string>::iterator itLines = strValues.begin();
while(itLines != strValues.end())
{
oFile << *itLines << std::endl;
++itLines;
}
oFile.close();
RemoveData(&pData, 1);
}IV-D-4. ODBC▲
Open DataBase Connectivity est un format de communication entre les base de données et les clients. Ce système est composé d'une API, puis de drivers. Pour chaque type de base (SQL Server, Oracle, db2 etc.), un driver est nécessaire. Celui-ci s'installe au niveau du système d'exploitation.
Son utilisation est assez rigide, et plutôt bas niveau, par conséquent, j'ai rajouté des classes utilitaires dans la bibliothèque kinUtils, que je ne détaillerai pas ici mais que vous pourrez retrouver dans les sources téléchargeable. Si l'utilisation de cette API vous intéresse, vous pouvez vous documenter ici
Le plus important à savoir est que vous pouvez récupérer des enregistrements de la base paquet par paquet dont la taille peut être variable au cours de la lecture. Aussi, les valeurs des données son transmises en binaire, d'où le IProperty::FromVoid(void*).
Je n'ai testé, et un peu rapidement, la connexion ODBC qu'avec SQL Server 2005. Des différences sont à prévoir pour être 100% compatibles avec d'autres SGBD.
Concernant le mapping, pour chaque type, il référence la table en base correspondant, puis associe ses propriété aux champs correspondants. Voyons ce que cela donne. Aussi, comme nous avons décidé que pour chaque type la source de données pouvait être différente, alors chacun d'entre eux indiquera la chaîne de connexion à la base de données.
<ODBC>
<BOOK TABLE="TBOOKS">
<CONNECT_STRING>DRIVER=SQL Server;SERVER=127.0.0.1\SQLEXPRESS;UID=user;PWD=pass;</CONNECT_STRING>
<FIELDS>
<FIELD>
<BASE>USR_ID</BASE>
<PROPERTY>ID</PROPERTY>
</FIELD>
<FIELD>
<BASE>USR_LOGIN</BASE>
<PROPERTY>LOGIN</PROPERTY>
</FIELD>
<FIELD>
<BASE>USR_PASS</BASE>
<PROPERTY>PASS</PROPERTY>
</FIELD>
<FIELD>
<BASE>USR_AGE</BASE>
<PROPERTY>AGE</PROPERTY>
</FIELD>
<FIELD>
<BASE>USR_CAR_ID</BASE>
<PROPERTY>CAR_ID</PROPERTY>
</FIELD>
</FIELDS>
</BOOK>
<AUTHOR TABLE="...">
...
</AUTHOR>
</ODBC>Dans les sources, une gestion de pool de connexion a été créé, une évolution serait de regrouper les entités utilisant la même base de données afin de limiter les connexion inutiles (par exemple si les livres et les auteurs utilisent la même base, nous les branchons sur le même pool limitant ainsi les connexions).
Concernant la structure de stockage des données, nous arrivons à ceci :
/*!
* \brief Structure de correspondance champ/propriété
*/
struct SField
{
std::string m_strFieldName; /*!< Le nom du champ en base. */
std::string m_strPropertyName; /*!< La propriété. */
};
/*!
* \brief Identifiant de l'index d'ordonnancement par insertion.
*/
struct SOrderedAsInserted{};
/*!
* \brief Identifiant de l'index d'ordonnancement par les champs.
*/
struct SOrderedAsFields{};
/*!
* \brief Identifiant de l'index d'ordonnancement par les propriétés.
*/
struct SOrderedAsProperties{};
typedef boost::multi_index::multi_index_container<SField, // Container de SField
boost::multi_index::indexed_by< // référencé par
boost::multi_index::sequenced<boost::multi_index::tag<SOrderedAsInserted>>, // insertion
boost::multi_index::ordered_unique< // champs
boost::multi_index::tag<SOrderedAsFields>,
boost::multi_index::member<SField,std::string,&SField::m_strFieldName>>,
boost::multi_index::ordered_unique< // propriétés
boost::multi_index::tag<SOrderedAsProperties>,
boost::multi_index::member<SField,std::string,&SField::m_strPropertyName>>
>
> TMappingSet; /*!< Type de stockage du mapping. */
typedef TMappingSet::index<SOrderedAsInserted>::type TMappingByInsertion; /*!< Type de l'index par insertion. */
typedef TMappingSet::index<SOrderedAsFields>::type TMappingByFields; /*!< Type de l'index par champs. */
typedef TMappingSet::index<SOrderedAsProperties>::type TMappingByProperties; /*!< Type de l'index par propriétés. */
/*!
* \brief Structure de l'ensemble du mapping pour une entité.
*/
struct SEntityData
{
std::string m_strTableName; /*!< Le nom de la table correspondante. */
std::string m_strConnectString; /*!< La chaîne de connexion à utiliser. */
TMappingSet m_Fields; /*!< Le mapping champ/propriété. */
};
typedef std::map<std::string, SEntityData> TEntityMapping; /*!< Table de correspondance entre les entités et leur données de mapping. */
TEntityMapping m_oMapping; /*!< Type de stockage des données de ce mapping. */
Vous savez utilisez les dictionnaires de la STL ainsi que les multi-index, donc nous n'allons pas détailler le reste de la gestion de ce mapping.
Passons aux méthodes du connecteur.
IV-D-4-1. Create▲
template<class T>
CData<T>* CODBCConnector<T>::Create(std::map<std::string, std::string>* pValues)
{
std::string strFields = "";
std::string strValues = "";
T* tNewData = CreateData();
CDataPropertyIterator<T> propIter;
while(propIter.HasNext())
{
const std::string& rstrProperty = propIter.GetPropertyName();
std::map<std::string, std::string>::iterator it = pValues->find(rstrProperty);
if(it != pValues->end())
{
IProperty& rProperty = propIter.GetProperty(*tNewData);
if(strFields.size() > 0)
strFields += ", ";
strFields += ODBCMapping.GetField(SDataTrait<T>::CODE, rstrProperty);
if(strValues.size() > 0)
strValues += ", ";
strValues += (rProperty.IsNum() ? "" : "'") +
(rProperty.IsNum() ? it->second : Replace(it->second, "'", "''")) +
(rProperty.IsNum() ? "" : "'");
rProperty.FromString(it->second);
}
propIter.Next();
}
std::string strQuery = "INSERT INTO " + ODBCMapping.GetTable(SDataTrait<T>::CODE) + " ("
+ strFields + ") VALUES (" + strValues + ")";
CODBCQuery* pQuery = m_db->CreateQuery(strQuery, 10);
long lAffected = pQuery->GetAffectedRows();
m_db->ReleaseQuery(pQuery);
return tNewData;
}IV-D-4-2. Load▲
template<class T>
void CODBCConnector<T>::Load()
{
std::string strQuery = "";
CDataPropertyIterator<T> propIter;
while(propIter.HasNext())
{
if(strQuery.size() > 0)
strQuery += ", ";
strQuery += ODBCMapping.GetField(SDataTrait<T>::CODE, propIter.GetPropertyName());
propIter.Next();
}
strQuery = "SELECT " + strQuery + " FROM " + ODBCMapping.GetTable(SDataTrait<T>::CODE);
std::vector<CData<T>*> vecAlreadyExistsData;
vecAlreadyExistsData.reserve(CGesManager::GetInstance().GetCount<T>());
CDataIterator<T> dataIter; CData<T>* tExistsData = 0;
while((tExistsData = dataIter.GetData()) != 0)
{
vecAlreadyExistsData.push_back(tExistsData);
dataIter.Next();
}
unsigned long ulDataToLoad = GetCount();
NotifyBeginLoad(ulDataToLoad);
std::vector<CData<T>*> vecNewDatas;
vecNewDatas.reserve(ulDataToLoad);
CODBCQuery* pQuery = m_db->CreateQuery(strQuery, 10);
int iColCount = pQuery->GetColumnCount();
unsigned long ulLoading = 0;
while(pQuery->GetNext())
{
NotifyLoading(++ulLoading, ulDataToLoad);
T& tTempData = CData<T>::GetModel();
for(int i = 0; i < iColCount; i++)
{
const std::string& rstrColName = pQuery->GetColumnName(i);
const std::string& rstrPropertyName = ODBCMapping.GetProperty(SDataTrait<T>::CODE, rstrColName);
tTempData.GetProperty(rstrPropertyName)->FromVoid(pQuery->GetValue<void*>(i));
}
bool bNew = true;
std::vector<CData<T>*>::iterator existsIt = vecAlreadyExistsData.begin();
while(existsIt != vecAlreadyExistsData.end())
{
if((*existsIt)->IsSame(tTempData))
{
(*existsIt)->CopyFrom(tTempData); // Mise à jour
bNew = false;
}
++existsIt;
}
if(bNew)
{
CData<T>* poData = CreateData();
poData->CopyFrom(tTempData);
vecNewDatas.push_back(poData);
}
}
m_db->ReleaseQuery(pQuery);
if(vecNewDatas.size() > 0)
AddNewData(&vecNewDatas[0], static_cast<unsigned long>(vecNewDatas.size()));
NotifyEndLoad(ulDataToLoad);
}IV-D-4-3. Update▲
template<class T>
void CODBCConnector<T>::Update(CData<T>* pData)
{
std::string strQuery = "";
std::string strWhere = "";
CDataPropertyIterator<T> propIter;
while(propIter.HasNext())
{
IProperty& rProperty = propIter.GetProperty(*pData);
const std::string& rstrProperty = propIter.GetPropertyName();
if(CGesManager::GetInstance().IsIdent<T>(rstrProperty))
{
if(strWhere.size() > 0)
strWhere += " AND ";
strWhere += ODBCMapping.GetField(SDataTrait<T>::CODE, rstrProperty) + " = " +
(rProperty.IsNum() ? "" : "'") +
(rProperty.IsNum() ? rProperty.ToString() : Replace(rProperty.ToString(), "'", "''")) +
(rProperty.IsNum() ? "" : "'");
}
else
{
if(strQuery.size() > 0)
strQuery += ", ";
strQuery += ODBCMapping.GetField(SDataTrait<T>::CODE, rstrProperty) + " = " +
(rProperty.IsNum() ? "" : "'") +
(rProperty.IsNum() ? rProperty.ToString() : Replace(rProperty.ToString(), "'", "''")) +
(rProperty.IsNum() ? "" : "'");
}
propIter.Next();
}
strQuery = "UPDATE " + ODBCMapping.GetTable(SDataTrait<T>::CODE) + " SET " + strQuery + " WHERE " + strWhere;
CODBCQuery* pQuery = m_db->CreateQuery(strQuery, 10);
long lAffected = pQuery->GetAffectedRows();
m_db->ReleaseQuery(pQuery);
}IV-D-4-4. Delete▲
template<class T>
void CODBCConnector<T>::Delete(CData<T>* pData)
{
std::string strQuery = "";
CDataPropertyIterator<T> propIter;
while(propIter.HasNext())
{
IProperty& rProperty = propIter.GetProperty(*pData);
const std::string& rstrProperty = propIter.GetPropertyName();
if(CGesManager::GetInstance().IsIdent<T>(rstrProperty))
{
if(strQuery.size() > 0)
strQuery += " AND ";
strQuery += ODBCMapping.GetField(SDataTrait<T>::CODE, rstrProperty) + " = " +
(rProperty.IsNum() ? "" : "'") +
(rProperty.IsNum() ? rProperty.ToString() : Replace(rProperty.ToString(), "'", "''")) +
(rProperty.IsNum() ? "" : "'");
}
propIter.Next();
}
strQuery = "DELETE FROM " + ODBCMapping.GetTable(SDataTrait<T>::CODE) + " WHERE " + strQuery;
CODBCQuery* pQuery = m_db->CreateQuery(strQuery, 10);
long lAffected = pQuery->GetAffectedRows();
m_db->ReleaseQuery(pQuery);
}IV-D-5. La fabrique▲
Nous avons donc quelques connecteur concrets, il ne reste plus qu'à répondre à la question "quel connecteur pour quel entité ?". Pour se faire, nous établissons un mapping entre le nom des entités, et un code de connecteur :
<IOCONFIG>
<BOOKS MODE="ODBC"/>
<AUTHOR MODE="XML"/>
<EDITOR MODE="CSV"/>
</IOCONFIG>Vous avez une idée de comment gérer ce mapping en mémoire, pas vraiment besoin de détailler là dessus, passons à la création du connecteur.
template<class T>
class CGesData : public IGesData
{
protected:
/*!
* \brief Constructeur.
*/
CGesData();
/*!
* \brief Destructeur.
*/
virtual ~CGesData();
private:
/*!
* \brief Obtient le connecteur IO de ce gestionnaire.
*
* \return Le connecteur IO.
*/
IIoConnector<T>* GetIoConnector();
IIoConnector<T>* m_pIoConnector; /*!< Connecteur de données. */
};
template<class T>
CGesData<T>::CGesData()
: m_pIoConnector(0)
{
}
template<class T>
CGesData<T>::~CGesData()
{
if(m_pIoConnector)
{
delete m_pIoConnector;
m_pIoConnector = 0;
}
}
template<class T>
IIoConnector<T>* CGesData<T>::GetIoConnector()
{
if(!m_pIoConnector)
m_pIoConnector = CIoFactory::Get().CreateConnector<T>();
return m_pIoConnector;
}IV-D-6. Branchement sur les Ges▲
Rajoutons les fonctions de manipulation IO au niveau des gestionnaires
template<class T>
class CGesData : public IGesData
{
protected:
/*!
* \brief Charge les données.
*/
void Load();
/*!
* \brief Met à jour une donnée dans la source.
*
* \param pData La donnée.
*/
void Update(CData<T>* pData);
/*!
* \brief Supprime une donnée dans la source.
*
* \param pData La donnée à supprimer.
*/
void Delete(CData<T>* pData);
/*!
* \brief Crée une donnée en base.
*
* \param pValues La map des propriétés/valeurs des propriétés.
* \return La donnée créée.
*/
CData<T>* Create(std::map<std::string, std::string>* pValues = 0);
};
template<class T>
void CGesData<T>::Load()
{
GetIoConnector()->Load();
}
template<class T>
void CGesData<T>::Update(CData<T>* pData)
{
GetIoConnector()->Update(pData);
}
template<class T>
void CGesData<T>::Delete(CData<T>* pData)
{
GetIoConnector()->Delete(pData);
}
template<class T>
CData<T>* CGesData<T>::Create(std::map<std::string, std::string>* pValues)
{
return GetIoConnector()->Create(pValues);
}N'oublions pas d'effectuer la redirection au niveau du point d'entrée (CGesManager), et désormais, nous pouvons faire ceci :
// Notre config IO
//<IOCONFIG>
// <BOOKS MODE="ODBC"/>
// <AUTHOR MODE="XML"/>
// <EDITOR MODE="CSV"/>
//</IOCONFIG>
// Initialisation de "qui est branché sur quoi
IOFactory.SetXml(rstrXml);
// Enregistrement des mappings utilisés
ODBCMapping.SetXml("xml/ODBCMapping.xml"); // Ira chercher dans la base référencé par la chaîne de connexion lié au livres
CSVMapping.SetXml("xml/CSVMapping.xml"); // Ira chercher dans le fichier CSV
XMLMapping.SetXml("xml/XMLMapping.xml"); // Ira chercher dans le fichier XML
// Et on attaque direct
GesMgr.Load<CBook>();
GesMgr.Load<CAuthor>();
GesMgr.Load<CEditor>();Il y a pas mal de fichiers externes (mapping, données etc.). Admettons qu'il y ai un problème, le boulot sera assez "dérangeant" de remonter l'algorithmie pour trouver d'où cela provient. C'est pourquoi il faut prévenir (par des exceptions ou un message dans les logs) un maximum. Surtout qu'avec le gestionnaire des logs que nous avons, l'utilisateur peut le brancher sur la console ou dans un espace de son IHM et par conséquent avoir tout ce qu'il lui faut sous les yeux en cas de disfonctionnement.