


III. L'équipement▲
Un bon artisan n'étant pas grand chose sans ses outils, définissons ceux dont nous devons nous munir.
III-A. La gestion des erreurs▲
L'erreur est humaine... mais pas que. Durant l'exécution du programme utilisateur, plusieurs disfonctionnements peuvent survenir comme l'échec d'ouverture d'un fichier, un problème de mémoire, réseau etc. Aussi, il se peut que nous ou notre utilisateur fasse une fausse manipulation, des erreurs d'inattention, de déconcentration, une mauvaise configuration ou autre, ce qui est tout à fait légitime. Pour prévenir ces soucis, il va nous falloir les gérer. Non pas les régler à la place du "fautif", mais l'amener facilement et efficacement à l'origine du problème afin qu'il puisse le régler dans un délai réduit, sans trop se casser la tête (si c'est un bon informaticien, il n'aimera pas ça).
Nous allons donc fournir une espèce de "stack trace" des erreurs, c'est à dire reproduire une pile d'erreurs comme "Le traitement a échoué" car "le module xxx n'a pu être initialisé" car "le fichier file.ini est inaccessible".
III-A-1. Les exceptions▲
Il y a plusieurs manières de faire pour notifier un disfonctionnement :
- L'une procédurale, consiste à renvoyer un booléen ou un code erreur à l'appelant pour dire "j'ai fait le boulot mais par contre j'ai eu des soucis"
- L'autre, plus dans un contexte de responsabilité (objet), consiste à tout arrêter et à notifier le supérieur qu'on ne peut plus avancer, via les exceptions, des objets encapsuleurs de problèmes.
C'est cette deuxième méthode que nous allons mettre en place, pour plusieurs raisons :
- Cela implique de ne peut pas passer un problème sous le manteau, créant d'autres problèmes de plus en plus sournois, nécessitant d'avantage de temps de correction.
- Les informations sur le disfonctionnement seront plus précises.
- Le code sera plus lisible, les valeurs de retour ne seront plus monopolisées, pas besoin de faire des assert.
- Une exception étant un objet, il peut encapsuler une éventuelle exception d'origine qui nous garantira une certaine traçabilité de problème, notre "stack trace".
Une bonne pratique est de faire un try/catch autour de la fonction main, pour qu'en cas de non traitement d'une exception, obtenir au moins un rapport explicite allant du plus haut niveau de l'erreur vers son plus bas niveau. Ce genre de rapport pourra être "copié/collé" directement dans un outils de suivi d'anomalie, ou automatiquement par mail si nous décidons d'implémenter une fonctionnalité d'envoi de disfonctionnement etc.
III-A-2. Conception▲
Une solution ressemble un peu au pattern composite, pour gérer la traçabilité. Définissons ce que possède une exception :
- Un message
- Une éventuelle exception à l'origine
- D'éventuelles causes
- D'éventuelles pistes de résolution
- D'éventuelles paramètres périphériques
Les exceptions spécifiques alimenteront les données et non le lanceur de celles-ci pour une simple raison, que les sous classes imposent un minimum de paramètres afin d'être assez explicite.
// Ce que nous ne proposerons pas :
CFileAccessException except;
except.SetMessage("Impossible d'accéder au fichier");
except.AddParam("FICHIER", strFile);
except.AddCause("Vous n'avez pas les droits d'accéder au fichier");
except.AddCause("Le fichier est verrouillé");
throw except;
// Et éviter ceci :
CFileAccessException except;
throw except; // Qui n'aurai aucune valeur informative si ce n'est que ça a planter
// Et mettons en place ceci :
throw CFileAccessException(strFile);
// En spécifiant les détails dans l'exception elle même
CFileAccessException::CFileAccessException(const std::string& rstrFile)
{
SetMessage("Impossible d'accéder au fichier");
AddParam(rstrFile);
AddCause("Vous n'avez pas les droits d'accéder au fichier");
AddCause("Le fichier est verrouillé");
}
Aussi, cette classe de base dérivera de std::exception et ne sera pas abstraite pour pouvoir lancer une exception dite "libre".
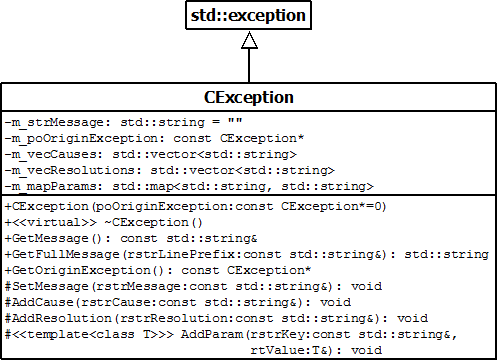
Au fur et à mesure que nous aurons besoin de lancer de nouvelles exception, nous feront hériter d'avantage de classe de la même manière.
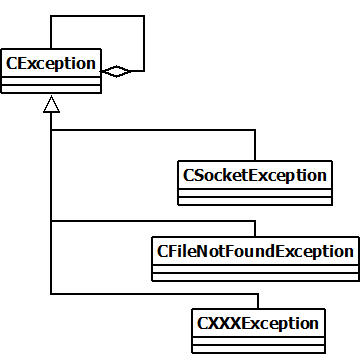
Voyons le code de l'exception de base :
/*!
* \brief Classe de base de nos exceptions.
*
* Toute exception peut contenir une exception d'origine.
*/
class CException
{
public :
/*!
* \brief Constructeur par défaut.
*
* \param [in] poOriginException L'éventuelle exception à l'origine de celle-ci.
* \param [in] rstrMessage Le message associé à cette exception.
*/
CException(const CException* poOriginException = 0);
/*!
* \brief Destructeur.
*/
virtual ~CException();
/*!
* \brief Obtient l'exception à l'origine de celle-ci.
*
* \return L'exception à l'origine de celle-ci.
*/
const CException* GetOriginException() const;
/*!
* \brief Obtient le message descriptif de cette exception.
*
* \return Le message descriptif de cette exception.
*/
virtual const char* what() const;
/*!
* \brief Obtient la description complète de cette exception.
*
* \param [in] rstrLinePrefix Le préfixe à appliquer à chaque ligne de cette description.
* \return La description complète de cette exception.
*/
std::string GetFullMessage(const std::string& rstrLinePrefix = "") const;
protected :
/*!
* \brief Positionne le message de cette exception.
*
* \param [in] rstrMessage Le message.
*/
void SetMessage(const std::string& rstrMessage);
/*!
* \brief Ajoute une cause à cette description.
*
* \param [in] rstrCause La cause à ajouter à cette exception.
*/
void AddCause(const std::string& rstrCause);
/*!
* \brief Ajoute un paramètre utile à connaître pour décrire cette exception.
*
* \param [in] rstrKey La clé du paramètre.
* \param [in] rtValue La valeur du paramètre.
*/
template<class T> void AddParam(const std::string& rstrKey, const T& rtValue);
/*!
* \brief Ajoute une résolution à cette exception.
*
* \param [in] rstrResolution La résolution à ajouter.
*/
void AddResolution(const std::string& rstrResolution);
private:
std::string m_strMessage; /*<! Le message descriptif de cette exception */
const CException* m_poOriginException; /*!< L'exception à l'origine de celle-ci. */
typedef std::vector<std::string> TVecCauses; /*!< Type pour stocker les causes. */
TVecCauses m_oVecCauses; /*!< La liste des causes possibles de cette exception. */
typedef std::vector<std::string> TVecResolutions; /*!< Type pour stocker les résolutions. */
TVecResolutions m_oVecResolutions; /*!< La liste des résolutions possibles. */
typedef std::map<std::string, std::string> TMapParams; /*!< Type pour mapper les paramètres et leurs valeurs. */
TMapParams m_oMapParams; /*!< La liste des paramètres additionnels. */
};
Le rapport pourra être généré alors de cette ainsi, dans la fonction GetFullMessage()
std::string CException::GetFullMessage(const std::string& rstrLinePrefix) const
{
std::string sWhat = "";
sWhat += rstrLinePrefix;
sWhat += "--> " + m_strMessage;
sWhat += "\n";
if(m_oVecCauses.size() > 0)
{
sWhat += rstrLinePrefix;
if(m_oVecCauses.size() > 1)
sWhat += "\t*Causes possibles :\n";
else
sWhat += "\t*Cause possible :\n";
for each(std::string sCauseIt in m_oVecCauses)
{
sWhat += rstrLinePrefix;
sWhat += "\t\t- ";
sWhat += sCauseIt + "\n";
}
}
if(m_oVecResolutions.size() > 0)
{
sWhat += rstrLinePrefix;
if(m_oVecResolutions.size() > 1)
sWhat += "\t*Résolutions possibles :\n";
else
sWhat += "\t*Résolution possible :\n";
for each(std::string sResolutionIt in m_oVecResolutions)
{
sWhat += rstrLinePrefix;
sWhat += "\t\t- ";
sWhat += sResolutionIt + "\n";
}
}
if(m_oMapParams.size() > 0)
{
sWhat += rstrLinePrefix;
if(m_oMapParams.size() > 1)
sWhat += "\t*Paramètres :\n";
else
sWhat += "\t*Paramètre :\n";
for each(const std::pair<std::string, std::string> oParamIt in m_oMapParams)
{
sWhat += rstrLinePrefix;
sWhat += "\t\t- ";
sWhat += oParamIt.first + " : " + oParamIt.second + "\n";
}
}
if(m_poOriginException != 0)
{
sWhat += rstrLinePrefix;
sWhat += "\t*Origine :\n";
sWhat += rstrLinePrefix;
sWhat += m_poOriginException->GetFullMessage("\t\t");
}
return sWhat;
}
Puis une exception particulière :
/*!
* \brief Exception levée lorsque l'accès au fichier de log de l'utilisation de la mémoire présente un problème.
*/
class CFileAccessException : public CException
{
public:
/*!
* \brief Constructeur.
*
* \param [in] rstrFilename Le nom du fichier dont l'accès a échouée.
* \param [in] poOriginException L'éventuelle exception à l'origine de celle-ci.
*/
CFileAccessException(
const std::string& rstrFilename,
const CException* poOriginException = 0)
{
SetMessage("Impossible d'accéder au fichier");
AddCause("Le nom du fichier est incorrect.");
AddCause("Le fichier est verrouillé.");
AddCause("Vous n'avez pas les droits d'accéder à ce fichier.");
AddResolution("Essayez de l'ouvrir manuellement");
AddParam("Nom du fichier", rstrFilename);
}
};Désormais, chaque classe pourra être livrée avec ses propres "problèmes potentiels" sous forme d'exception.
III-B. La gestion de la mémoire▲
Cet partie reprend ce tutoriel auquel les fonctions malloc, calloc, realloc et free on été rajoutées.
S'il y a bien quelque chose de facile à faire en C++, c'est de créer des fuites de mémoire.
Cette bibliothèque ayant pour vocation de gérer des centaines de milliers de données, une libération de mémoire
oubliée peut poser de sérieux problème à l'exécution mais surtout lors du débogage si nous n'avons
pas vraiment d'informations permettant de cibler le problème facilement et par conséquent rapidement.
III-B-1. La technique▲
Le but du jeu est d'intercepter toute allocation/libération dynamique faite durant l'exécution d'un
programme pour les comptabiliser, avant de les rediriger vers la CRT comme si de rien n'était.
A la fin de l'exécution, nous envoyons le différentiel dans un fichier avec des informations sur l'endroit
où se trouvent l'allocation qui n'a pas été supprimée (fichier + ligne et éventuellement fonction).
Bien entendu, cela doit rester transparent
pour l'utilisateur, en d'autres terme il ne devra pas à avoir à taper ce genre de code :
CBook* pBook = 0;
#ifdef _DEBUG
pBook = SafeNew(CBook);
#else
pBook = new CBook();
#endif // _DEBUG
...
#ifdef _DEBUG
SafeDelete(pBook);
#else
delete pBook
#endif // _DEBUGLe meilleur moyen d'intercepter ces opérations sur la mémoire est de redéfinir les opérateurs/fonctions standards disponibles à l'utilisateur, via des macros utilisant nos propres opérateurs/fonction qui eux, redirigeront la demande vers notre gestionnaire.
III-B-2. Les différents moyen d'allouer/libérer une ressource▲
| Allocation | Désallocation |
|---|---|
| new | delete |
| new[] | delete[] |
| malloc/calloc/realloc | free |
En factorisant les fonctionnalités, nous obtenons ce tableau :
| Opérateur/Fonction standard | Redirection dans le gestionnaire |
|---|---|
| new new[] malloc calloc |
Alloc |
| realloc | Realloc |
| delete delete[] free |
ToDelete / Free |
III-B-2-1. Le type d'allocation▲
Comme nous souhaitons préserver les éventuelles erreurs du développeur dans l'utilisation de la mémoire, pour chaque bloc alloué nous devons les "typer" selon la manière dont ils ont été alloués.
/*!
* Enumère les types de manipulation de la mémoire possibles.
*/
enum E_ALLOC_TYPE
{
E_OPERATOR, /*< Par les opérateurs new et delete. */
E_OPERATOR_ARRAY, /*!< Par les opérateurs new[] et delete[]. */
E_C_STYLE /*!< Par les fonctions malloc, calloc, realloc et free. */
};III-B-2-2. Le block de mémoire▲
Pour chaque allocation, nous allons stocker des informations sur le bloc alloué comme la taille, le type ainsi que le lieu de la demande.
/*!
* \struct SBlock
* \brief Représente un bloc de mémoire.
*/
struct SMemBlock
{
std::size_t m_stSize; /*!< Taille allouée. */
std::string m_strFile; /*!< Fichier source où ce bloc a été alloué. */
unsigned int m_uiLine; /*!< Numéro de ligne du fichier source où ce bloc a été alloué. */
std::string m_strFunction; /*!< Le nom de la fonction qui a alloué ce bloc. */
E_ALLOC_TYPE m_eType; /*!< Indique si ce bloc est un tableau ou pas. */
};III-B-2-3. L'allocation▲
Pour allouer un block, nous créons une fonction d'allocation avec toutes les informations requises pour caractériser ce block. Nous ajoutons également un flags de mise à 0 de la mémoire pour gérer calloc ainsi qu'un autre pour indiquer s'il faut gérer ce bloc ou pas.
/*!
* \brief Alloue un bloc de mémoire.
*
* \param [in] stSize La taille à allouer (en octet).
* \param [in] rstrFile Le fichier dans lequel a été réclamé l'allocation.
* \param [in] uiLine La ligne du fichier source où a été réclamé l'allocation.
* \param [in] rstrFunction Le nom de la fonction
* \param [in] eType Le type d'allocation.
* \param [in] bManage Indique si le gestionnaire de mémoire doit gérer cette allocation.
* \param [in] bSetMemory Indique s'il faut initialiser la mémoire avec des 0.
* \return Un pointeur sur la zone allouée.
*/
void* Alloc(std::size_t stSize,
const std::string& rstrFile,
unsigned int uiLine,
const std::string& rstrFunction,
E_ALLOC_TYPE eType,
bool bManage = true,
bool bSetMemory = false);Cette fonction commence par allouer la mémoire, grâce à malloc ou calloc si la demande de mise à 0 a été positionnée. Puis elle construit le bloc grâce aux paramètres données afin de le stocker dans un dictionnaire référençant le pointeur avec ce bloc. Enfin, elle renverra un pointeur vers l'espace mémoire alloué.
III-B-2-4. La réallocation▲
Nous créons également une fonction de réallocation.
/*!
* \brief Réalloue un bloc de mémoire.
*
* \param [in] pvPointer Le pointeur vers la mémoire à réallouer.
* \param [in] stSize La taille à réallouer (en octet).
* \param [in] rstrFile Le fichier dans lequel a été réclamé la réallocation.
* \param [in] uiLine La ligne du fichier source où a été réclamé la réallocation.
* \param [in] rstrFunction Le nom de la fonction
* \return Un pointeur sur la zone réallouée.
*/
void* Realloc(void* pvPointer,
std::size_t stSize,
const std::string& rstrFile,
unsigned int uiLine,
const std::string& rstrFunction);Cette fonction ira chercher le bloc initialement alloué. Puis, elle appellera realloc avant de mettre à jour le pointeur ainsi que la taille allouée.
III-B-2-5. La libération▲
La libération est un peu spéciale, elle se décompose en deux temps. En effet, nous ne pouvons pas rediriger les opérateurs delete et delete[] avec les informations sur le fichier, la ligne ou la fonction de la demande.
Nous devons alors posséder une pile de libérations à remplir en amont avant d'appeler la fonction qui libèrera finalement la mémoire.
/*!
* \brief Stock les infos sur le prochain bloc à libérer.
*
* \param [in] rstrFile Le fichier dans lequel a été réclamé l'allocation.
* \param [in] uiLine La ligne du fichier source où a été réclamé l'allocation.
* \param [in] rstrFunction La fonction.
*/
void ToDelete(const std::string& rstrFile, unsigned int uiLine, const std::string& rstrFunction);
/*!
* \brief Libère un bloc en mmoire.
*
* \param [in] pvPointer Le pointeur vers la zone à libérer.
* \param [in] eType Le type de libération.
*/
void Free(void* pvPointer, E_ALLOC_TYPE eType);III-B-2-6. Les autres fonctions▲
Nous proposons également une fonction qui renvoi la taille actuellement allouée par nos données dans l'application.
/*!
* \brief Obtient la quantité de mémoire actuellement allouée par ce gestionnaire.
*
* \return La quantité de mémoire actuellement allouée par ce gestionnaire.
*/
unsigned long GetAllowedSize();Le gestionnaire, qui possède ces méthodes, devra être unique. Nous passerons par une variable statique, le concept de Singleton est détaillé plus tard.
/*!
* \brief Obtient l'instance unique de cette classe.
*
* \return L'instance unique de cette classe.
*/
static CMemoryManager& GetInstance();
// Implémentation
CMemoryManager& CMemoryManager::GetInstance()
{
static CMemoryManager oInstance;
return oInstance;
}III-B-2-7. Les exceptions possibles▲
Les problèmes ci dessous donneront lieu à un lancement d'exception :
| Problème | Exception |
|---|---|
| Echec d'ouverture du fichier de log | CMemoryFileException |
| Echec d'allocation/réallocation | CAllocException |
| La méthode de libération est différente de celle de l'allocation | CBadFreeException |
| Tentative de réallocation d'un pointeur non créé avec malloc/calloc | CBadReallocException |
III-B-2-8. Le rapport de fuite▲
En fin d'exécution du programme (lorsque la variable statique se détruit), les blocs restants sont des fuites. Nous les indiquerons dans un fichier de log.
void CMemoryManager::~CMemoryManager()
{
if(m_mapAllouedBlock.size() > 0)
ReportLeaks();
else
// pas de fuite
}
void CMemoryManager::ReportLeaks()
{
// Parcourt des blocks restant
// Inscription des infos dans le fichier de log
}III-B-2-9. La redirection des opérateurs/fonctions standards▲
Notre gestionnaire est prêt à l'emploi, il ne reste plus qu'à redéfinir les différents moyens d'allouer/libérer la mémoire.
Nous utiliseront des macros. Un fichier sera à inclure en début de notre code pour activer le gestionnaire, un autre pour le désactiver. Commençons par redéfinir les opérateurs
inline void* operator new(std::size_t stSize, const char* szFilename, unsigned int uiLine, const char* sFunction)
{
return MemMgr.Alloc(stSize, szFilename, uiLine, sFunction, kin::CMemoryManager::E_OPERATOR);
}
inline void* operator new[](std::size_t stSize, const char* szFilename, unsigned int uiLine, const char* sFunction)
{
return MemMgr.Alloc(stSize, szFilename, uiLine, sFunction, kin::CMemoryManager::E_OPERATOR_ARRAY);
}En redéfinissant les opérateurs new/new[] de cette manière, le compilateur nous réclamera de redéfinir les opérateur delete et delete[] respectant la même signature
inline void operator delete(void* pvPointer, const char* szFilename, unsigned int uiLine, const char* sFunction) throw()
{
MemMgr.ToDelete(szFilename, uiLine, sFunction);
MemMgr.Free(pvPointer, kin::CMemoryManager::E_OPERATOR);
}
inline void operator delete[](void* pvPointer, const char* szFilename, unsigned int uiLine, const char* sFunction) throw()
{
MemMgr.ToDelete(szFilename, uiLine, sFunction);
MemMgr.Free(pvPointer, kin::CMemoryManager::E_OPERATOR_ARRAY);
}Il faut également redéfinir les opérateurs de libération avec leur signature standard.
inline void operator delete(void* pvPointer) throw()
{
MemMgr.Free(pvPointer, kin::CMemoryManager::E_OPERATOR);
}
inline void operator delete[](void* pvPointer) throw()
{
MemMgr.Free(pvPointer, kin::CMemoryManager::E_OPERATOR_ARRAY);
}Et enfin les macros de redirection pour utiliser nos opérateurs ou rediriger les fonctions standards vers notre gestionnaire.
#define new new(__FILE__, __LINE__, __FUNCTION__)
#define delete MemMgr.ToDelete(__FILE__, __LINE__, __FUNCTION__), delete
#define malloc(sz) MemMgr.Alloc(sz, __FILE__, __LINE__, __FUNCTION__, kin::CMemoryManager::E_C_STYLE);
#define calloc(nb, sz) MemMgr.Alloc(sz * nb, __FILE__, __LINE__, __FUNCTION__, kin::CMemoryManager::E_C_STYLE, true);
#define realloc(ptr,sz) MemMgr.Realloc(ptr, sz, __FILE__, __LINE__, __FUNCTION__);
#define free(ptr) MemMgr.ToDelete(__FILE__, __LINE__, __FUNCTION__), MemMgr.Free(ptr, kin::CMemoryManager::E_C_STYLE)Puis les suppressions de macro pour désactiver le gestionnaire
#undef new
#undef delete
#undef malloc
#undef calloc
#undef realloc
#undef freeIII-B-2-10. Utilisation et rendu▲
Pour l'utiliser, il faut activer le gestionnaire, c'est à dire inclure le fichier de redéfinition des macros en début de code, puis celui de désactivation en fin de code.
#include <kinUtils/Memory/EnableMemoryManager.h>
int main()
{
int* i1 = new int(3);
int* i2 = new int[3];
int* i3 = (int*)malloc(2 * sizeof(int));
int* i4 = (int*)realloc(i3, sizeof(int));
int* i5 = (int*)calloc(2, sizeof(int));
delete i1;
delete[] i2;
free(i5);
}
#include <kinUtils/Memory/DisableMemoryManager.h>Ce code ci dessus nous amènera à ce rapport :
----------- Rapport de mémoire -----------
++ Allocation | 0x008867B0 | 4 octets | kintestapp.cpp | main (6)
++ Allocation | 0x00886928 | 12 octets | kintestapp.cpp | main (7)
++ Allocation | 0x00886970 | 8 octets | kintestapp.cpp | main (8)
++ Réallocation | 0x00886970 | -4 octets | kintestapp.cpp | main (9)
++ Allocation | 0x00886CE0 | 8 octets | kintestapp.cpp | main (10)
-- Désallocation | 0x008867B0 | 4 octets | kintestapp.cpp | main (12)
-- Désallocation | 0x00886928 | 12 octets | kintestapp.cpp | main (13)
-- Désallocation | 0x00886CE0 | 8 octets | kintestapp.cpp | main (14)
----------- Fuite(s) détectée(s) -----------
-> 0x00886970 | 4 octets | kintestapp.cpp | main (8)
!! 1 bloc non-libéré 4 octets !!
Si nous allouons un bloc de mémoire via le gestionnaire et que nous libérons correctement la mémoire mais dans une portion de code où le gestionnaire n'est plus actif, cela créera de fuites fictives.
Par conséquent, tout comme les anti inclusions multiples, il faut avoir le réflex de l'activer en début de code et le désactiver en fin de code.
III-C. Le singleton▲
Le singleton est un Design Pattern permettant de garantir l'unicité de l'instance d'une classe. En général ce sont des gestionnaires (de log, de connexion, de ressources etc.). Pour assurer ceci, il y a deux manière :
- Utiliser un membre statique comme nous l'avons fait pour le gestionnaire de mémoire et le renvoyer via une méthode
- Utiliser un pointeur statique initialisé à 0. L'instance sera construite au premier appel
Le constructeur sera donc privé.
Avantages et inconvénients de ces deux méthodes :
| Type d'instance | Avantages | Inconvénients |
|---|---|---|
| Instance statique | Nous ne nous soucions pas de la destruction | Nous ne contrôlons pas la destruction |
| Instance dynamique | Nous décidons quand et dans quel ordre sont détruits les singletons | L'utilisateur doit veiller à bien détruire les singletons, dans le bon ordre |
Nous utiliseront donc la seconde version, pour avoir le contrôle des destructions. En voici les principes :
Nous avons utilisé la méthode du membre statique dans le gestionnaire de mémoire étant donné qu'il n'était pas possible de brancher le gestionnaire de mémoire sur lui même sous peine de créer des inclusions récursives.
Voyons un premier jet de cette solution :
/*!
* \brief Un gestionnaire.
*/
class CMyManager
{
public:
/*!
* \brief Récupère l'instance.
*
* \return L'instance.
*/
static CMyManager& GetInstance();
/*!
* \brief Détruit l'instance.
*/
static void Destroy();
private:
/*!
* \brief Constructeur privé.
*/
CMyManager();
/*!
* \brief Destructeur privé.
*/
~CMyManager();
static CMyManager* s_pInstance; /*!< Instance unique. */
};
static CMyManager* CMyManager::s_pInstance = 0;
CMyManager::CMyManager() {}
CMyManager::~CMyManager() {}
CMyManager& CMyManager::GetInstance()
{
if(!s_pInstance)
s_pInstance = new CMyManager();
return s_pInstance;
}
void CMyManager::Destroy()
{
if(s_pInstance)
{
delete s_pInstance;
s_pInstance = 0;
}
}
Naturellement nous n'allons pas répéter cette mécanique à chaque fois que nous aurons besoin de faire un Singleton. Nous devons construire une classe de base qui s'en chargera.
Comme nous ne connaissons pas le type qui héritera de notre classe, nous la templarisons. Ainsi, le pointeur de l'instance sera de type T et GetInstance() renverra du T&.
/*!
* \brief Classe de base de tous les singletons.
*/
template<class T>
class CSingleton
{
public:
/*!
* \brief Renvoi l'instance de la classe.
*
* \return L'instance unique de cette classe.
*/
static T& Instance();
/*!
* \brief Détruit l'instance de la classe.
*/
static void Destroy();
protected :
/*!
* \brief Constructeur.
*/
CSingleton();
/*!
* \brief Destructeur.
*/
~CSingleton();
private:
static T* s_pInstance; /*!< L'instance (unique) de cette classe. */
};Définissons deux macros d'initialisation pour rendre les "formalités" plus simples :
- L'une permettant de rendre amis le gestionnaire avec sa classe de base, le singleton. Ceci permettra d'autoriser CSingleton à accéder au constructeur privé du gestionnaire.
- L'autre permettant d'initialiser le pointeur statique du singleton.
/*!
* \brief Donne l'accès au singleton à la construction du type encapsulé.
*/
#define SINGLETON_DECLARE(Class) \
public : \
friend class kin::CSingleton<Class>; \
static Class& GetInstance(); \
private:
/*!
* \brief Initialise un singleton.
*/
#define SINGLETON_IMPL(Class) \
template <> Class* kin::CSingleton<Class>::ms_ptInstance = 0; \
Class& Class::GetInstance() \
{ \
return kin::CSingleton<Class>::GetInstance(); \
} /*!< Initialise le pointeur static d'un singleton. */Il nous suffit alors d'étendre cette classe pour obtenir un singleton.
class CMyManager : public CSingleton<CMyManager>
{
SINGLETON_DECLARE(CMyManager)
...
};
// Dans un .cpp
SINGLETON_IMPL(CMyManager)III-D. La gestion des logs▲
Cette partie a été reprise de cet article en y ajoutant la possibilité de brancher des logger "externes" à l'unité logiciel. Notre librairie finale passera en DLL, le programme voudra peut-être rediriger les logs de cette bibliothèque sans sa gestion.
La plupart des logiciels possède une gestion de logs permettant de tracer ce qui se passe durant son exécution, et ainsi avoir une base d'analyse pour différents cas (dysfonctionnement, temps etc.). Voici les fonctionnalités que nous nous apprêtons à réaliser :
- Etre utilisable via les opérateurs de flux, pour obtenir un code plus propre et pratique.
- Pouvoir inscrire un message composé de chaîne de caractères, entier, flottant ou objets métier sans passer par des conversions en chaîne au préalable, cela ne serait pas productif et alourdirait le code utilisateur.
- Pouvoir facilement créer et brancher une destination de log. Où vont aller ces messages ? Dans un fichiers ? Texte, XML ? Ou une base de données, un socket etc. ? Brancher un nouveau "logger" doit être simple, sans en changer l'utilisation du gestionnaire.
III-D-1. Les loggers▲
Nous allons utiliser le patron de méthode. Ce Design Pattern consiste à créer une classe de base qui fera appel à une ou plusieurs méthode(s) virtuelle(s) afin de proposer un comportement commun de tous les loggers tout en respectant leur spécificité. Ici, chaque logger se différencie par sa méthode d'écriture. L'un écrira dans un fichier, un autre sur la console, un troisième sur une fenêtre de Debug, puis pourquoi pas dans un socket où sur une partie de l'IHM etc. L'avantage est que pour créer un nouveau logger, une seule méthode, bien ciblée et spécifique, sera à implémenter.
class CLogger
{
private:
virtual void Write(const std::string& rstrMessage) = 0;
};Ceci fait, nous pouvons nous appuyer sur cette méthode en interne pour proposer... du confort avec l'opérateur de flux d'insertion "<<".
/*!
* \brief Opérateur d'insertion dans un flux.
*
* \param [in] rtToLog Le T à logger.
*/
template <class T> ILogger& ILogger::operator <<(const T& rtToLog)
{
std::ostringstream Stream;
Stream << rtToLog;
Write(Stream.str());
return *this; // Nous renvoyons le logger pour pouvoir cumuler les appels à <<
}Exemple de logger qui inscrit les message dans la sortie Debug de l'IDE :
class CDebugLogger : public CLogger
{
private:
virtual void Write(const std::string& rstrMessage);
};
void CDebugLogger::Write(const std::string& rstrMessage)
{
OutputDebugString(rstrMessage.c_str());
}
CDebugLogger logger;
int i = 0;
float f = 0.;
logger << "Un message de log, nous y mettons un entier " << i << " puis un flottant " << f;III-D-2. Le gestionnaire de logs▲
Nous allons sûrement utiliser plusieurs loggers.
class CFileLogger : public CLogger { ... };
class CConsoleLogger : public CLogger { ... };
class CSocketLogger : public CLogger { ... };
// etc...Il serait bien dommage d'imposer à l'utilisateur ce genre de code
g_fileLogger << "Un message de log, nous y mettons un entier " << i << " puis un flottant " << f;
g_socketLogger << "Un message de log, nous y mettons un entier " << i << " puis un flottant " << f;
#ifdef _DEBUG
g_debugLogger << "Un message de log, nous y mettons un entier " << i << " puis un flottant " << f;
g_consoleLogger << "Un message de log, nous y mettons un entier " << i << " puis un flottant " << f;
#endif // <i>DEBUGNous devons donc créer un gestionnaire (donc Singleton) qui va encapsuler les loggers à prendre en compte. En fait, le gestionnaire de log est un simple logger, qui tient une liste de loggers. Sa méthode Write ne fera que transmettre le message aux loggers "branchés" dessus.
/*!
* \brief Gestionnaire de log.
*/
class CLogManager : public CSingleton<CLogManager>, public ILogger
{
SINGLETON_DECLARE(CLogManager);
public:
/*!
* \brief Branche un logger à ce gestionnaire.
*
* \param pLogger Le logger.
* \param bExtern Indique si le logger est extern à l'instance applicative.
*/
void AddLogger(ILogger* pLogger, bool bExtern = false);
private:
/*!
* \brief Constructeur.
*/
CLogManager();
/*!
* \brief Destructeur.
*/
virtual ~CLogManager();
/*!
* \brief Log un message.
*
* \param [in] rstrMessage Le message à logger.
*/
void Write(const std::string& rstrMessage);
typedef std::map<ILogger*, bool> TMapLoggers; /*!< Type de stockage des loggers internes. */
TMapLoggers m_mapLoggers; /*!< La liste des loggers enregistrés. */
};
#define Log CLogManager::GetInstance() // Petit racourcit pratique.
A la destruction, le gestionnaire supprimera les loggers enregistrés. Mais comme nous allons faire une DLL, le gestionnaire possèdera des loggers issus d'une autre unitaire logicielle (notre .exe).
Par conséquent, à l'enregistrement des loggers, nous rajoutons un flag indiquant si le logger est externe ou pas. S'il l'est, le gestionnaire ne le détruira pas.
Voyons comment l'initialisation se passe :
Log.AddLogger(new CFileLogger("kin.log"));
Log.AddLogger(new CSocketLogger("pc-de-control", 3159));
// Si nous sommes en debug, nous branchons aussi le cadre de sortie de l'IDE, ainsi que la console.
#ifdef _DEBUG
Log.AddLogger(new CConsoleLogger());
Log.AddLogger(new CDebugLogger());
#endif // DEBUGEnfin, voici comment s'utilisera ce gestionnaire
Log << "Un message de log, nous y mettons un entier " << i << " puis un flottant " << f;"UMLement" parlant, nous avons codé ceci :
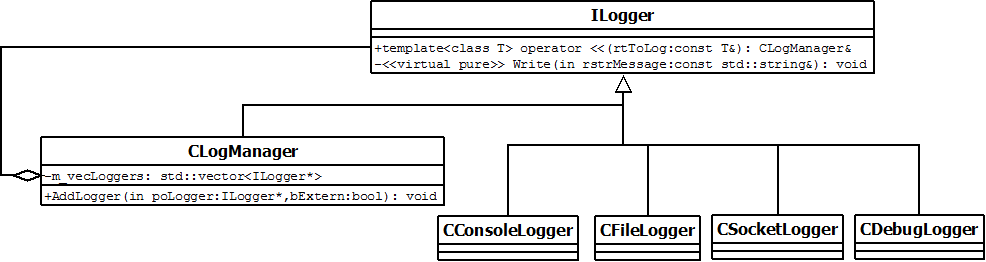
Nous verrons qu'en fin d'article, une fois le passage en DLL effectué, nous pourrons faire ceci :
Log.AddLogger(new CFileLogger("kin.log"));
Log.AddLogger(new CSocketLogger("pc-de-control", 3159));
#ifdef _DEBUG
Log.AddLogger(new CConsoleLogger());
Log.AddLogger(new CDebugLogger());
#endif // DEBUG
// Redirection des messages de la DLL dans ceux de l'exe.
kinAddLogger(Log); // Log, le gestionnaire étant lui même un logger, ça passe.Par la suite, pourquoi ne pas préfixer les messages des différentes unités ? Pour obtenir par exemple
kinTestApp - Début d'exécution
kinBusiness - Chargement des clients, 2884 données, 23 ms
kinTestApp - Fin d'exécutionIII-D-3. Convertisseurs chaînes/types▲
Les classes ci dessous ont été reprises du moteur graphique de loulou.
Pour transformer tout type de donnée en chaîne de caractères et inversement, le plus pratique est de passer par les flux de chaînes, produisant ce genre de code :
int i; float f;
// Construction d'une chaîne
std::ostringstream ostream;
steam << i << f;
std::string strString = stream.str();
// Extraction des valeur depuis la chaîne.
std::istringstream istream(strString);
istream >> f >> i;Nous allons encapsuler ces conversions dans des objets, puis leur donner plus de clarté d'utilisation. Commençons par le constructeur de chaîne. Par défaut, il est vide mais nous laissons la possibilité de l'initialiser avec une valeur. Par la suite, nous pourrons le remplir d'avantage via d'autres valeurs. Et enfin, nous récupèrerons la chaîne résultante.
/*!
* \brief Constructeur de chaîne à partir de tout type de données.
*/
class CStringBuilder
{
public :
/*!
* \brief Constructeur.
*/
CStringBuilder();
/*!
* \brief Constructeur avec construction initiale.
*
* \tparam T Le type de la donnée à partir de laquelle initialiser cette instance.
* \param [in] rtValue La valeur initiale.
*/
template <typename T> CStringBuilder(const T& rtValue);
/*!
* \brief Alimente ce constructeur de chaîne.
*
* \tparam T Le type de la donnée source.
* \param [in] rtValue La valeur à ajouter à ce constructeur de chaîne.
*/
template <typename T> inline CStringBuilder& operator ()(const T& rtValue);
/*!
* \brief Opérateur de conversion en chaîne de caractère.
*
* \return La chaîne construite.
*/
inline operator std::string();
private:
std::ostringstream m_oOutStream; /*!< Le flux de sortie interne. */
};Voici l'implémentation des méthodes importantes
template <typename T>
inline CStringBuilder::CStringBuilder(const T& rtValue)
{
m_oOutStream << rtValue;
}
template <typename T>
inline CStringBuilder& CStringBuilder::operator ()(const T& rtValue)
{
m_oOutStream << rtValue;
return *this;
}
inline CStringBuilder::operator std::string()
{
return m_oOutStream.str();
}Quand à l'utilisation, elle se résume à ceci
CStringBuilder builder; int i = 2; float f = 3.4;
std::string str = builder(i)(f);Intéressons nous maintenant à l'extracteur. Le principe est le même, il encapsule un flux d'entrée de chaînes puis propose des facilités d'utilisation pour reconstruire les données dans leur type.
/*!
* \brief Extracteur de chaînes dans un type choisit.
*/
class CStringExtractor
{
public :
/*!
* \brief Constructeur.
*
* \param [in] rstrText La chaîne initiale.
*/
CStringExtractor(const std::string& rstrText = "");
/*!
* \brief Remplit une valeur.
*
* \tparam T Le type de la valeur à templir.
* \param [in] rtValue La valeur à remplir.
*/
template <typename T> CStringExtractor& operator ()(T& rtValue);
/*!
* \brief Indique si cet extracteur est vide ou non.
*/
bool Empty();
/*!
* \brief Réalimente cet extracteur.
*
* \param [in] rstrText Le texte avec lequel réalimenter cet extracteur.
*/
void Push(const std::string& rstrText);
private :
std::istringstream m_oInStream; /*!< Le lfux d'entrée interne. */
};Voilà l'implémentation
template <typename T>
inline CStringExtractor& CStringExtractor::operator ()(T& rtValue)
{
if (m_oInStream.str().size() == 0)
return *this;
if (!(m_oInStream >> rtValue))
{
if (m_oInStream.eof())
throw new CExtractorConvertException(typeid(T).name());
else
throw new CExtractorEmptyException(typeid(T).name());
}
return *this;
}
inline bool CStringExtractor::Empty()
{
return m_oInStream.eof();
}
inline void CStringExtractor::Push(const std::string& rstrText)
{
m_oInStream.clear();
m_oInStream.str(rstrText.c_str());
}Et l'utilisation :
CStringExtractor oExtractor("2 3,4");
int i = 0; float f = 0.;
oExtractor(i)(f);III-E. Les outils externes▲
Nous allons également utiliser des outils externes, autant les installer de suite.
III-E-1. libxml2▲
Pour manipuler les fichiers XML, nous utilisons libxml2, un peu moins performante que xerces-c, mais plus facile à utiliser. Téléchargez la bibliothèque à l'adresse ftp://fr.rpmfind.net/pub/libxml/ [ftp://fr.rpmfind.net/pub/libxml/]. Allez dans le répertoire "win32" puis prenez les packages libxml2 (dernière version), iconv et zlib. Décompressez tout ça dans votre répertoire de libs externes puis indiquez à votre compilateur, pour chacune d'entre elle les répertoires include et lib de ces bibliothèques.
III-E-2. boost▲
Boost est un ensemble de bibliothèques utilitaires, performantes et portables dont il est difficile de passer à côté. Voyons comment les installer.
Commencez par télécharger la dernière version à l'adresse https://www.boost.org/users/download/ ainsi que Boost Jam, compilée (pour ma part ce sera ntx86). Décompressez le tout dans un même répertoire, puis ouvrez l'invite de commande de Visual Studio et dirigez vous dans le répertoire où vous avez mis les sources.
Tapez ensuite "bjam toolset=msvc --build-type=complete install"
Patientez désormais un petit peut, 3/4h selon votre machine, et vous obtiendrez un répertoire "C:/boost" contenant les sources ainsi que les libs compilées. Placez le dans votre répertoire de libs, puis indiquez à votre éditeur les sous-répertoire include et lib produits.
Je compile tout pour être sûr qu'il ne manquera rien, mais pour plus de précisions sur l'installation et les options de compilation de boost : Installer et utiliser Boost/Boost.TR1 avec Visual C++.